TensorFlow 安装,运行,实现常见神经网络模型。
TensorFlow 是 Google 开源库,用于机器学习和深度神经网络方面的研究,但这个系统的通用性使其也可广泛用于其他计算领域。
环境搭建
参考官网提供的环境搭建方法: TensorFlow install 。
安装
可以在 Ubuntu 系统的 python 环境中运行 TensorFlow ,主要有两种安装方式:
pippip install tensorflow安装最新稳定的CPU-only包。docker
基于docker运行TensorFlow容器,docker提供了虚拟技术,能和本地环境隔离,推荐使用这种方式;安装好docker环境后,下载镜像docker pull tensorflow/tensorflow。
运行
基于 docker 运行 TensorFlow 容器,有多种 tag 可选,参考 docker tensorflow 官网 ;这里使用 python 3 和 Jupyter Notebook 来运行环境:
1 | xmt@server138:~/share$ docker run -it --rm -v /home/xmt/share/notebooks:/tf/notebooks -p 8888:8888 tensorflow/tensorflow:latest-py3-jupyter |
执行完后,可以在浏览器中输入 http://ip:8888 来访问 Jupyter Notebook , token 为上面输出的那串数字!
Jupyter Notebook 教程
Jupyter Notebook 是网页化的 Python 编辑器,快速方便交互。
快捷键
Jupyter 和 vim 一样分为命令模式和编辑模式,使用 ESC 进入命令模式;如下是部分快捷键:
- 命令模式
L显示当前单元格行号shift + L显示所有单元格行号
- 编辑模式
tab自动补全shift + tab查看当前函数说明shift + enter运行当前单元,并选中下一单元ctrl + enter只运行当前单元
使用 Alt 键可以多列选择。
特殊功能
在 Jupyter notebook 中支持命令安装,图形显示等等。
- 安装
python包Jupyter的每个cell可以执行unix command,具体方法是在command前加一个!号。比如使用pip install安装matplotlib包时,键入!pip install matplotlib。
其他示例:查看python版本!python --version;运行python文件!python myfile.py。 %运算符- 使用
matplotlib显示图形时,输入命令%matplotlib inline - 将本地的
.py文件加载到当前单元%load test.py - 运行本地
.py文件%run file.py
- 使用
扩展
安装扩展: pip install jupyter_contrib_nbextensions; jupyter contrib nbextension install
AutoPEP8
代码格式化工具:pip install autopep8,安装完毕后,在扩展中勾选autopep8。
基础知识
Tensor 张量
Tensor 张量,表示一个数据结构,有三个最基本的属性:名称 name ,形状 shape ,数据类型 dtype 。张量用来存放数据(通常是多维数组,维度即为形状),比如:
1 | c = tf.constant([[1,2,3],[4,5,6]]) |
输出结果为:
1 | Tensor("Const_10:0", shape=(2, 3), dtype=int32) |
示例中张量 c 名称为 Const_10 ,形状为可以存放 2*3 的数据,数据类型为 int32 。
我们用阶表示张量的维度:
- 0 阶张量
即为标量,表示一个单独数:S=123。 - 1 阶张量
表示一个一维数组: `S=[1, 2, 3] 。 - 2 阶张量
表示一个二维数组,它可以有i行j列个元素,每个元素可以通过下标来索引到:S=[[1, 2, 3], [4, 5, 6]]。
判断张量是几阶的,可以通过等号后面中括号的个数来看出来,比如 m=[[[...] 表示为 3 阶的。
会话
会话 Session ,执行计算过程; Tensor 只描述了数据,所有 Tensor 的操作也只描述了计算过程,而运算都是通过会话来实现的。计算过程使用下面结构:
1 | with tf.Session() as sess: |
run 来执行运算过程。
神经网络
常用函数
- 神经网络参数
指神经元线上的权重,参数初始值通常使用随机数,这些参数也是最终我们需要求出的值。通过张量来描述:w = tf.Variable(tf.truncated_normal(shape, stddev=0.1))。 - 前向传播
搭建模型的计算过程,让模型具有推理能力,可以针对一组输入给出响应的输出。比如某个神经元的前向传播描述为:输入乘以权重后,加上偏置,再通过激活函数;表示为y1 = tf.nn.relu(tf.matmul(x, w1) + b1)。 - 反向传播
训练模型参数,使神经网络模型在训练数据上的损失函数最小,比如在所有参数上用梯度下降。损失函数loss即计算得到的预测值和已知结果的差距。如果预测值y与已知答案y_,常见损失函数有:- 均方差
mse:mse=tf.reduce_mean(tf.square(y-y_)) - 交叉熵
ce:ce=tf.reduce_mean(y_*tf.log(tf.clip_by_value(y, 1e-12, 1.0)))
- 均方差
常见分类器
Sigmoid分类器,也就是Sigmoid激活函数,用于二分类Softmax分类器,用于多分类;n分类应用中: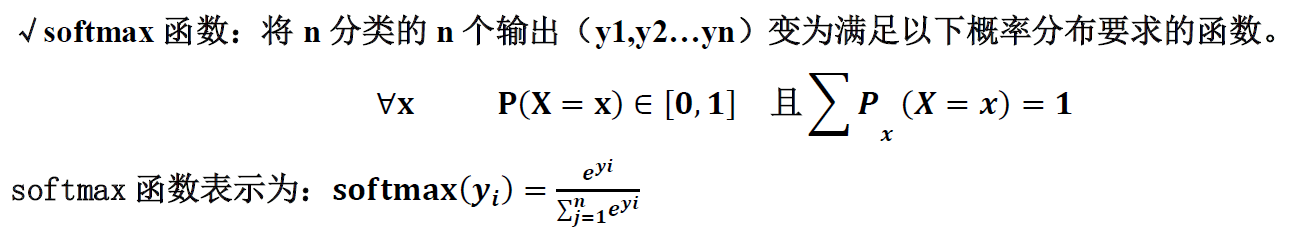
softmax函数在n分类应用中,模型会有n个输出y1, y2,..., yn,其中yi表示第i种情况出现的概率;这n个输出经过softmax函数后,可以得到符合概率分布的分类结果。一般让模型的输出经过softmax函数,以获得输出分类的概率分布,再与标准答案对比,求出交叉熵,得到损失函数:1
2
3ce = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y,
labels=tf.argmax(y_, 1))
cem = tf.reduce_mean(ce)
学习率
学习率 learning rate :决定每次参数更新的幅度。当学习率选择过大时会出现震荡不收敛;选择过小时会出现收敛速度慢的情况。在训练过程中,参数的更新向着损失函数梯度下降的方向。
指数衰减学习率:学习率随着训练轮数变化而动态更新,计算公式如下:
1 | Learning_rate=LEARNING_RATE_BASE*LEARNING_RATE_DECAY |
对应函数为:
1 | global_step = tf.Variable(0, trainable=False) |
示例代码,初始值为 0.1 ,每 100000 轮更新一次学习率,衰减率为 0.96 :
1 | global_step = tf.Variable(0, trainable=False) |
滑动平均
滑动平均:记录了一段时间内模型中所有参数 w 和 b 各自的平均值,利用滑动平均值可以增强模型的泛化能力。
滑动平均影子计算公式: shadow_variable = decay * shadow_variable + (1 - decay) * variable
衰减率 decay=min(decay, (1 + num_updates) / (10 + num_updates)) ,初始值通常为接近 1 的数,比如: 0.99 , 0.999 等等。
1 | # Create an ExponentialMovingAverage object |
正则化
在损失函数中给每个参数 W 加上权重,引入模型复杂度指标,从而抑制模型噪声,减小过拟合。
正则化有 L1, L2 的区分,计算公式如下:
1 | loss_l1 = tf.contrib.layers.l1_regularizer(REGULARIZER)(w) |
其中 w 为希望被正则化的参数, REGULARIZER 为标量乘法器的值(即正则化后再乘以这个比例),通常初始为 0.001 。正则化参数后,优化损失函数:
1 | tf.add_to_collection('losses', |
神经网络搭建八股
神经网络搭建,参考:
- 北大mooc tensorflow 笔记
- 助教整理 pdf
- 网友整理的代码实现:
搭建大体遵循如下流程:
- 准备数据集,提取特征,作为输入喂给神经网络
- 搭建
NN结构,从输入到输出;即搭建计算图NN前向传播算法,计算输出结果 - 大量特征数据喂给
NN,迭代优化NN参数NN反向传播算法,优化参数训练模型 - 使用训练好的模型预测和分类
基于神经网络的机器学习主要分为两个过程:训练过程和使用过程。训练过程指前三步是反复循环迭代的过程,参数优化完成后保存固化;使用过程指使用训练过程固化的参数,实现特定应用。
实际应用中,通常使用现有成熟的网络结构,喂入新的数据,训练相应模型,判断是否能对喂入的新数据作出正确响应,再适当更改网络结构,反复迭代,直到找到最优结构和参数。
整理成 python 的常用格式为:
导入模块,生成模拟数据集
1
2
3import
常量定义
生成数据集前向传播:定义输入、参数和输出
1
2
3x= y_= // 已知的输入和输出集
w1= w2= // 要求解的参数,通常先赋值随机参数
a= y= // 根据输入 x 和参数 w ,计算得到隐藏层及输出结果反向传播:定义损失函数,反向传播方法
1
2loss= // 根据已知输出 y_ 和计算得到的输出 y ,计算损失值
train_step= // 反向传播训练方法生成会话,训练指定轮数
神经网络断点续训
神经网络保存以及重新加载,这样有利于断点保护,当训练时间很长时,可以在某个时刻暂停保存,后续需要继续训练时,可以从此处开始。
保存
MODEL_SAVE_PATH 是神经网络参数保存的路径, MODEL_NAME 保存文件名的前缀;通常是在训练过程中,比如每 1000 轮保存一次参数。
1 | saver = tf.train.Saver() |
保存的文件通常是三个:
.meta文件,保存当前图的结构.index文件,保存当前参数名.data文件,保存当前参数
恢复
MODEL_SAVE_PATH 是神经网络参数保存的路径(不需要指定文件名)。
1 | saver = tf.train.Saver() |
恢复参数的滑动平均值
如果保存模型时,模型中采用了滑动平均,则参数的滑动平均值需要单独恢复加载:
在实例化 Saver 时,滑动平均参数直接传递到构造函数中:
1 | ema = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY) |
CNN 卷积神经网络
卷积
conv2d 卷积是将给定的 4 维的输入和卷积核张量,转换为输出 2 维张量,函数原型如下:
1 | #/usr/local/lib/python3.5/dist-packages/tensorflow/python/ops/gen_nn_ops.py |
input
输入张量,形状为input=[batch, in_height, in_width, in_channels],即每次处理batch张图片,每张图片有in_channels个通道数。filter
也称为卷积核kernel,形状为filter=[filter_height, filter_width, in_channels, out_channels],通道数和输入保持一致;out_channels输出通道数,也表示卷积核的个数,即从输入提取多少个特征;也就是一张图片,可以提取出out_channels张特征图。strides
滑动步长,表示卷积核横向和纵向上每次移动的步长。padding
在输入图像外圈填充一圈像素,也就是扩大输入图像的大小;有两个可能值:valid
表示不需要填充像素。same
表示输出和输入的大小相同,padding补全的大小为p=(f-1)/2,使用全零填充。
卷积后输出张量的形状为 output=[batch, out_height, out_width, out_channels] ,其中 out_height, out_width 计算方式如下:
如果输入数据大小为 n*n ,卷积核为 f*f ,滑动步长为 s , padding 填充为 p ,则输出大小为 (n+2p-f)/s + 1 。
1 | import tensorflow as tf |
输出结果形状如下:
1 | <tf.Variable 'Variable_16:0' shape=(1, 5, 5, 3) dtype=float32_ref> |
池化
最大池化和平均池化函数原型:
1 | def max_pool(input, ksize, strides, padding, |
input/value
输入张量,形状为[batch, height, width, channels]ksize
池化核的大小,形状为[batch, height, width, channels],通常我们不会在batch, channels上做池化,所以一般设置为[1, height, width, 1],仅仅给出池化核的大小。
strides, padding 和卷积中的意义一样。
1 | input = tf.Variable(tf.random_normal([1, 4, 4, 2])) |
输出结果形状如下:
1 | <tf.Variable 'Variable_36:0' shape=(1, 4, 4, 2) dtype=float32_ref> |
TensorBoard
TensorFlow 虚拟可视化技术,能记录和查看整个网络的相关信息,通过网页来查看相关信息;支持如下几个操作:
tf.summary.scalar标量,也就是常量参数tf.summary.image图片显示,常见图片分类中会显示训练图片tf.summary.audio声音相关tf.summary.text文本相关tf.summary.histogram柱状图
除了这些操作外, TensorBoard 还会默认显示整个神经网络的结构图 Graph 以及 Distributions (它是 histogram 的另外一种展示方式)。
计算图
计算图 Graph ,描述了神经网络的计算过程,是承载一个或多个计算节点的一张图,只搭建网络不运算。它是对神经网络的一个描述,描述了神经网络的组建方式,输入,参数,层数,输出等等。
基本用法
所有的
name_scope都会生成Graph中一个节点,双击这个节点可以展开节点看到更详细信息1
2
3
4# Input placeholders
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, 784], name='x-input')
y_ = tf.placeholder(tf.int64, [None], name='y-input')标量和柱状图
1
2
3
4
5
6
7
8
9
10
11def variable_summaries(var):
"""Attach a lot of summaries to a Tensor (for TensorBoard visualization)."""
with tf.name_scope('summaries'):
mean = tf.reduce_mean(var)
tf.summary.scalar('mean', mean)
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
tf.summary.scalar('stddev', stddev)
tf.summary.scalar('max', tf.reduce_max(var))
tf.summary.scalar('min', tf.reduce_min(var))
tf.summary.histogram('histogram', var)tf.summary.merge_all合并操作,生成所有汇总数据:一个序列化的Summary protobuf对象1
2
3
4merged = tf.summary.merge_all()
// 所有操作只能在 run 中生成数据,所以 merge 的结果为 run 返回值
summary, acc = sess.run(
[merged, accuracy], feed_dict=feed_dict(False))tf.summary.FileWriter将汇总的protobuf以文件的方式保存下来1
2
3
4// 指定 log 保存路径
train_writer = tf.summary.FileWriter(log_dir, sess.graph)
train_writer.add_summary(summary, i)
train_writer.close()
注意:每个 log 目录下只能保存一个 events.out.tfevents.** 事件日志,如果有多个日志只能显示最后一个。多个日志可以新建不同的目录单独保存,在 tensorboard 运行时,指定日志目录为其父目录就能查看所有的日志了。
运行 tensorboard
在 tf.summary.FileWriter 中会指定 log 保存路径,运行 tensorboard 时需要指定到这个路径: tensorboard --logdir=logs ,运行成功后,默认以 6006 端口来访问它,比如: http://ip:6006 。
1 | root@136b043c9daa:/tf/# tensorboard --logdir mnist_with_summaries/ |
注意:如果在服务器上通过 docker 运行 TensorFlow 环境,需要在 docker 启动镜像时,指定 6006 转发端口: -p 0.0.0.0:6006:6006 ,否则在客户端提示无法访问,参考 stackoverflow: How to use TensorBoard in a Docker container (on Windows)。
1 | docker run --name py3-jupyter -it -d --rm -v /home/share:/tf/py3-jupyter \ |
其中: 6006 为 tensorboard 转发端口; 8888 为 jupyter notebook 转发端口。
已有模型 pb 的可视化
对于已经存在的 pb 文件,可以通过 netron 在线查看,也可以使用代码保存 log 后通过 tensorboard 来查看图结构:
1 | import tensorflow as tf |
运行 tensorboard ,在 graph 页面双击生成的 mtcnn_graph 展开查看详细图结构信息。
TensorFlow 分布式
TensorFlow Lite
TensorFlow Lite 是 TensorFlow 的简化版本,用于手机或者 IOT 设备等,它的模型文件是 tflite 后缀;而 TensorFlow Mobile 被弃用,全面使用 Lite 。官方资料:
一个第三方在线查看 TensorFlow 模型 pb, tflite 文件的结构的网站:netron ;也可以通过 tensorboard 查看图结构。转换为 tflite 可能经常出现不支持的操作,对照着图结构可以清楚的看出该操作具体的位置,想办法规避或替换不支持的操作。
模型转换
通常使用 TensorFlow 训练出模型后,再将模型转换为 tflite 文件,参考官方模型转换指导 ,推荐使用 python api 的方式来实现,但是 TensorFlow python 接口个版本间差异较大,使用时参考官方最新提供的接口文档:python api 。
卷积神经网络
CNN
卷积神经网络的输入可以是任意形状None,但是转换为tflite必须要指定具体形状,可以在转换时先随便指定一个固定值,在实际调用时动态改变输入的形状set_tensor,参考stackoverflow: Input images with dynamic dimensions in Tensorflow-lite 。量化模型
浮点型转换为整型,相对于浮点型整个模型可以压缩到 1/4 ,但准确率只有几个点的下降;量化模型在手持设备上,速度有 2 倍以上的提升。pb文件转换为tflite1
2
3
4
5
6
7
8
9
10import tensorflow as tf
graph_def_file = "/path//mobilenet_v1_1.0_224/frozen_graph.pb"
input_arrays = ["input"]
output_arrays = ["MobilenetV1/Predictions/Softmax"]
converter = tf.lite.TFLiteConverter.from_frozen_graph(
graph_def_file, input_arrays, output_arrays)
tflite_model = converter.convert() // 转换
open("converted_model.tflite", "wb").write(tflite_model) // 保存文件转换为量化模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30import tensorflow as tf
graph_def_file = "/tf/py3-jupyter/04-Face/Mtcnn/model_check_point/mtcnn.pb"
tflite_quant_file = "/tf/py3-jupyter/04-Face/Mtcnn/model_check_point/mtcnn_quant.tflite"
output_arrays = ['pnet/prob1', # PNet face classification
'pnet/conv4-2/BiasAdd', # PNet BoundingBox Regression
'rnet/prob1', # RNet face classification
'rnet/conv5-2/conv5-2', # RNet BoundingBox Regression
'onet/prob1', # ONet face classification
'onet/conv6-2/conv6-2', # ONet BoundingBox Regression
'onet/conv6-3/conv6-3' # ONet Facial Landmark
]
input_arrays = ['pnet/input',
'rnet/input',
'onet/input']
// 卷积神经网络,必须给定具体形状
input_shapes = {'pnet/input': [1, 224, 224, 3],
'rnet/input': [1, 24, 24, 3],
'onet/input': [1, 48, 48, 3]}
converter = tf.lite.TFLiteConverter.from_frozen_graph(
graph_def_file, input_arrays, output_arrays, input_shapes)
converter.inference_type = tf.lite.constants.QUANTIZED_UINT8
converter.quantized_input_stats = {input_arrays[0]: (127.5, 128.), input_arrays[1]: (
127.5, 128.), input_arrays[2]: (127.5, 128.)} # mean, std_dev
converter.default_ranges_stats = (-1.0, 1.0)
tflite_quant_model = converter.convert()
open(tflite_quant_file, "wb").write(tflite_quant_model)
print("end...")
转换为量化模型时,需要指定 inference_type 为 QUANTIZED_UINT8 ,以及设置均值、标准差、最大值、最小值等等。转换为量化模型的接口随着 TensorFlow 版本升级,可能不一样,请参考最新接口。
有时候模型可以正确转换为 tflite 浮点型,但是量化时却失败,因为量化支持的操作比较少,根据错误信息,修改原始模型(使用支持量化的操作),再重新生成量化模型文件。
移植到 Android 手机 Java 方案
Android Studio 新建项目后,在 Gradle 文件中增加如下配置:
1 |
|
其中 aar 文件的源码可以在aar 源码中查看 。
Java 代码中加载 tflite 模型,并获取输入输出张量相关信息:
1 | private void loadTfLiteModel() { |
加载的模型使用类型为 MappedByteBuffer ,并初始化生成解释器 Interpreter ,通过它调用神经网络模型,得到输出结果:
1 | // 输入为 ByteBuffer 类型 |
- 输入为
ByteBuffer类型,并将输入数据逐个存入 - 输出为数组,维度为神经网络模型输出张量的阶
- 使用
tflite.run***()调用神经网络模型,得到输出结果 - 如果为卷积神经网络
CNN,即输入可以是任意形状,但是tflite只支持固定形状,需要动态调整
官方经典示例
其他
常见操作
遍历 pb 文件所有的节点信息
1 | import tensorflow as tf |
遍历 tflite 文件所有节点信息
1 | # 遍历 tflite 文件所有 tensor |
pb 转 tflite
转换时, output 必须和保存 pb 时一致,否则会出各种莫名其妙的问题,这些问题并不会提示你是因为 output 不一致。
1 | def freeze(sess,): |
常见问题
断点恢复
1 | NotFoundError: Key Variable/ExponentialMovingAverage_8 not found in checkpoint |
出现问题是因为运行完储存指令就调用,然而计算机已经有了训练好的神经网络,再调用神经网络会出问题。所以储存完后,需要在 jupyter notebook 上重启核,再运行程序即可。
或者使用 with tf.Graph().as_default() as tg: 恢复神经网络,再 restore 参数。
读取 tflite 的张量 tensor
1 | interpreter = tf.lite.Interpreter(model_path=tflite_file) |
运行时报错:
1 | RuntimeError: tensorflow/lite/kernels/conv.cc:224 input->dims->size != 4 (0 != 4)Node number 29 (CONV_2D) failed to prepare. |
解决思路,我们将第 29 个节点打印出来,看看它的 shape
1 | interpreter = tf.lite.Interpreter(model_path=tflite_file) |
打印结果为:
1 | {'quantization': (0.0, 0), 'name': 'onet/input', 'shape': array([], dtype=int32), 'index': 29, 'dtype': <class 'numpy.float32'>} |
可以看到第 29 个节点的 'shape': array([], dtype=int32) ,是空的,正常情况下 array 应该是一个 4 维数据,比如 [1, 224, 224, 3] ,因此我们从原始的 pb 文件中查看对应 onet/input 的形状:
1 | gf = tf.GraphDef() |
打印结果为:
1 | name: "onet/input" |
pb 文件中 onet/input 形状为 [-1, 48, 48, 3] ,也就是说,我们将 pb 转换为 tflite 时,没有包含这个信息。所以重新转换:
1 | input_name = ['pnet/input', |
numpy 处理后的数据类型默认 float64 ,而 tensorflow 中默认使用 float32 需要转换
1 | // 发生错误: |
查看该节点类型为 numpy.float32 的,而 numpy 默认操作数组时类型是 float64 ,需要转换:
1 | print(img.shape, img.dtype) |
pb 的 shape 为 None 时,即可以是任意形状,但是转换为 tflite 时,必须指定为具体数字
1 | // 设置输入数据时 |
解决方案,参考stackoverflow: Input images with dynamic dimensions in Tensorflow-lite
第一步,转换时先设置固定值:
1 | tflite_convert \ |
第二步,调用时先调整大小再调用:
1 | from tensorflow.contrib.lite.python import interpreter |
量化不支持的操作
Unimplemented: this graph contains an operator of type Neg for which the quantized form is not yet implemented.
1 |
|
TensorFlow 默认不支持 prelu 激活函数,需要自己实现;上面两种方式都能实现 prelu ,但是量化时不支持负号操作,所以改写成取最大值最小值来实现。
参考文档
- TensorFlow 官网
- github TensorFlow
- 官方示例
- w3cschool TensorFlow 教程-API描述
- 最详尽使用指南:超快上手Jupyter Notebook
- Jupyter Notebook快速入门教程
- Tensorflow基础知识
- 北大 mooc tensorflow 笔记
- 北大 mooc 助教整理 pdf
- Logistic 分类器与 softmax分类器
- Softmax函数
- 在线查看 TensorFlow 模型 pb, tflite 文件的结构
- TF-lite 模型结构解析
- Tensorflow 模型量化:Quantizing deep convolutional networks for efficient inference: A whitepaper 译文