MTCNN 人脸检测关键 5 点:眼、鼻、嘴。
概述
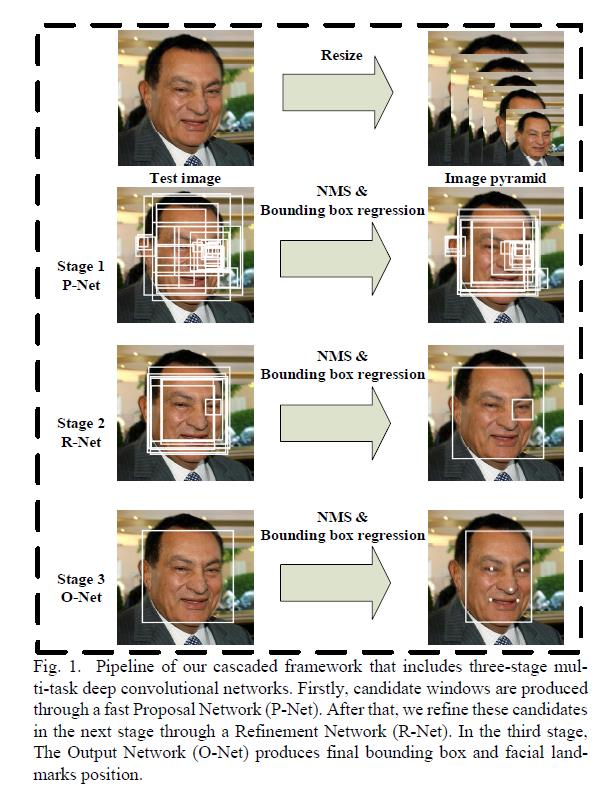
MTCNN 人脸检测模型由中国科学院深圳先进技术研究院,在 2016 年发布,通过三个网络级联实现人脸 5 个关键点(双眼、鼻、嘴)的定位检测;大致检测流程如下:
相关资源
- 人脸识别中
MTCNN多任务卷积论文:Multi-Task Convolutional Neural Network for Pose-Invariant Face Recognition MTCNN实现人脸关键点检测论文:Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks- 论文作者
kpzhang93代码仓库,包含最新的论文和代码:Github上官方代码实现 Facenet中基于kpzhang93提供的数据对齐人脸:Facenet 中使用 TensorFlow 实现的 MTCNN- 基于
davidsandberg/facenet提供的数据,转换为TensorFlow中的模型pb文件:vcvycy: MTCNN-TensorFlow-freeze-model vcvycy基于上面的模型pb文件,在Android上的实现:MTCNN TensorFlow mobile- 参考
kpzhang93的论文,自己准备数据,基于TensorFlow的实现完整的MTCNN并生成模型:AITTSMD: MTCNN-TensorFlow - 基于
AITTSMD训练的数据转换为tflite:pb 转 tflite WIDERFACE人脸数据集,常用于自己训练模型:WIDERFACE data- 人脸和关键 5 点数据集,需要翻墙下载(已下载到个人网盘):Deep Convolutional Network Cascade for Facial Point Detection
几个名词
Bounding box regression
边框回归,预测的框有可能不是完整的被检测到的物体,需要微调到到真实大小的框,这个预测框转换为真实框的过程叫做边框回归。IoUIoU: Intersec over Union交并比,也就是重叠度,计算的是预测框和真实框的交集和并集的比值,当IoU大于某个阈值(0.5)时,就认为预测框是正确的。常用于评价定位算法是否精准。NMSNMS: Non Maximum Suppression非极大值抑制,即只保留局部最大值,用于去掉重复的检测框,只保留局部最好的检测框,即检测分数最高的框。
模型结构
模型结构图
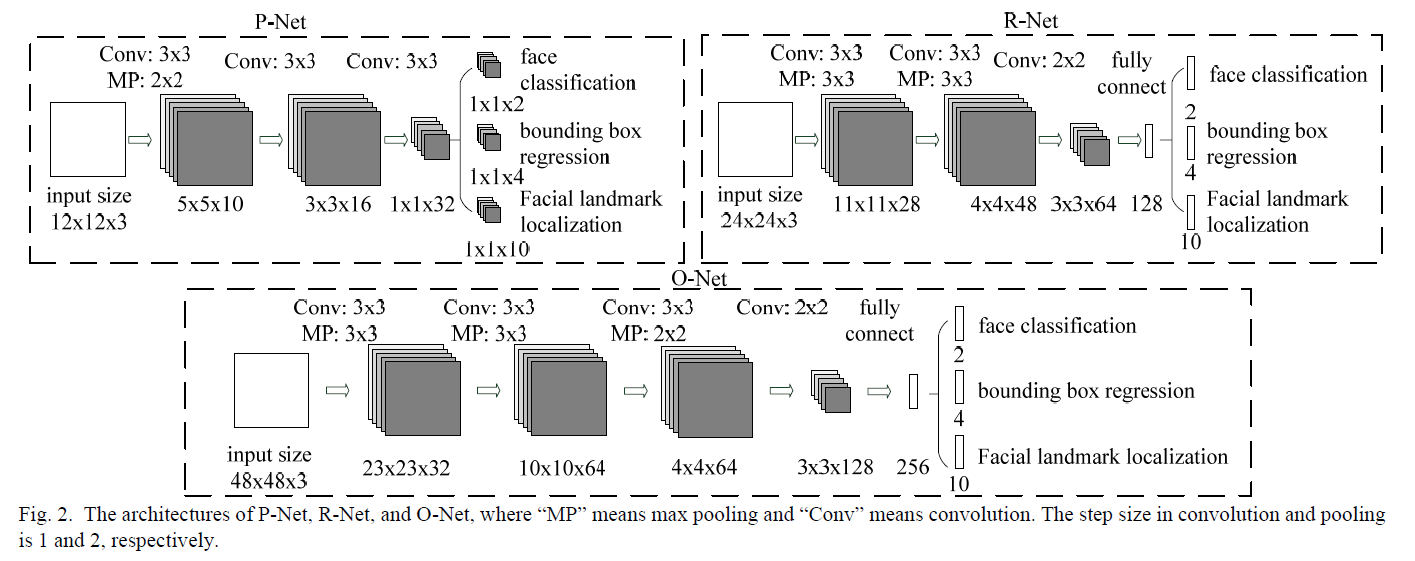
有三个独立的网络构成: P-Net, R-Net, O-Net 。
P-Net
P-Net: Proposal Network ,是全卷积网络,因此可以接受任意尺寸的输入图片,这里假定输入大小为 12*12*3 :
- 第一层:使用 10 个
3*3*3的卷积核,滑动步长为 1 ,padding为VALID,卷积输出大小为10*10*10;再经过2*2的池化核,滑动步长为 2 的Max Pooling,生成 10 个5*5的特征图 - 第二层:使用 16 个
3*3*10的卷积核,滑动步长为 1 ,padding为VALID,生成 16 个3*3的特征图 - 第三层:使用 32 个
3*3*16的卷积核,滑动步长为 1 ,padding为VALID,生成 32 个1*1的特征图 - 对于这 32 个
1*1的特征图,训练时分三部分并行处理:分类face classification, 回归框判断bounding box regression,轮廓点定位Facial landmark localization - 分类
face classification: 使用 2 个1*1*32的卷积核,生成 2 个1*1的特征图用于分类 - 回归框判断
bounding box regression:使用 4 个1*1*32的卷积核,生成 4 个1*1的特征图用于回归框判断 - 轮廓点定位
Facial landmark localization:使用 10 个1*1*32的卷积核,生成 10 个1*1的特征图用于人脸轮廓点的定位
R-Net
R-Net: Refine Network ,该网络先通过卷积然后再做全连接,也是分成三部分处理; R-Net 的输入为固定大小 24*24*3 ,但是输入个数由 P-Net 输出的候选框个数决定。
当 P-Net 处理完图像后,得到的候选回归框通过 NMS 去除冗余,并将候选框调整为正方形区域;从原始图片中截取出候选框大小的图片,并缩放为 24*24 大小,作为 R-Net 的输入,每个 24*24*3 大小的候选框会经过 R-Net 处理:
- 第一层:使用 28 个
3*3*3的卷积核,输出大小为22*22*28;再经过3*3的池化核,滑动步长为 2 的最大池化,生成 28 个11*11的特征图 - 第二层:使用 48 个
3*3*28的卷积核,输出大小为9*9*48;再经过3*3的池化核,滑动步长为 2 的最大池化,生成 48 个4*4的特征图 - 第三层:使用 64 个
2*2*48的卷积核,生成 64 个3*3的特征图 - 第四层:全连接层,64 个
3*3的特征图喂入全连接层后,输出大小为 128 ;训练时,从这里分成三部分处理:分类face classification, 回归框判断bounding box regression,轮廓点定位Facial landmark localization - 分类
face classification:全连接输入大小为 128 ,输出为人脸的 2 分类结果 - 回归框判断
bounding box regression:全连接输入大小为 128 ,输出为大小为 4 的回归框判断结果 - 轮廓点定位
Facial landmark localization:全连接输入大小为 128 ,输出为大小为 10 的轮廓点定位
O-Net
O-Net: Output Network ,该网络和 R-Net 很类似; O-Net 的输入为固定大小 48*48*3 ,但是输入个数由 R-Net 输出的候选框个数决定。
当 R-Net 处理完图像后,得到的候选回归框通过 NMS 去除冗余;从原始图片中截取出候选框大小的图片,并调整为 48*48 大小,作为 O-Net 的输入,每个 48*48*3 大小的候选框会经过 O-Net 处理:
- 第一层:使用 32 个
3*3*3的卷积核,输出大小为46*46*32;再经过3*3的池化核,滑动步长为 2 的最大池化,生成 32 个23*23的特征图 - 第二层:使用 64 个
3*3*32的卷积核,输出大小为21*21*64;再经过3*3的池化核,滑动步长为 2 的最大池化,生成 64 个10*10的特征图 - 第三层:使用 64 个
3*3*64的卷积核,输出大小为8*8*64;再经过2*2的池化核,滑动步长为 2 的最大池化,生成 64 个4*4的特征图 - 第四层:使用 128 个
2*2*64的卷积核,生成 128 个3*3的特征图 - 第五层:全连接层,128 个
3*3的特征图喂入全连接层后,输出大小为 256 ;训练时,从这里分成三部分处理:分类face classification, 回归框判断bounding box regression,轮廓点定位Facial landmark localization - 分类
face classification:全连接输入大小为 256 ,输出为人脸的 2 分类结果 - 回归框判断
bounding box regression:全连接输入大小为 256 ,输出为大小为 4 的回归框判断结果 - 轮廓点定位
Facial landmark localization:全连接输入大小为 256 ,输出为大小为 10 的轮廓点定位
损失函数
三个网络的损失函数分别为:
P-Net损失函数为二分类交叉熵R-Net, O-Net损失函数都为L2均方差
多任务训练时,不是每个示例的都需要使用三种损失函数,在 P-Net, R-Net 中, α 分类、候选框、定位的值为 1, 0.5, 0.5 ;在 O-Net 中, α 分类、候选框、定位的值为 1, 0.5, 1 ;对于 β∈(0,1) 。

模型小结
- 三个网络的卷积核的滑动步长都为 1 ,
padding都为VALID - 卷积后面激活函数为
PReLU - 三个网络池化核滑动步长都为 2
- 三个网络的输出都为三部分:分类
face classification, 回归框判断bounding box regression,轮廓点定位Facial landmark localization,但只有O-Net的轮廓定位点是有效的 P-Net使用了1*1的卷积来代替全连接,好处是输入可以是任意尺寸- 2 个人脸分类结果:第二个表示是人脸的分数
- 4 个回归框结果:分别对应回归框映射时左上右下映射参数
- 10 个轮廓点定位:表示 5 个关键点(左眼,右眼、鼻、嘴左边、嘴右边)的坐标,其中第 1 个和第 6 个表示左眼坐标,第 2 个和第 7 个表示右眼坐标,以此类推