算法:优先队列、堆、二叉堆、索引优先队列、堆排序等相关介绍。
基本概念
定义
优先队列 Priority queue :是这样一种数据结构,支持删除优先级最高元素和插入元素。通常有两种实现方式:
- 最大优先队列:支持删除最大元素
- 最小优先队列:支持删除最小元素
通用 API
1 | public class MaxPQ<Key> implements Iterable<Key> { |
优先队列的初级实现
- 数组实现无序
插入元素:直接插入到数组最后一列;删除最大元素:遍历数组找到最大元素,和最后一列交换后删除它。 - 数组实现有序
插入元素:类似插入排序,将所有较大元素向右移动一格使数组保持有序;删除元素:最大元素总是在数组最右边,直接删除。 - 链表实现
可以基于链表模拟栈操作,pop找到并返回最大元素并删除;push保证元素为逆序。


二叉堆
堆
堆 Heap 是一类特殊的数据结构的统称,堆通常是一个可以被看做一棵树的数组对象。堆总是满足下列性质:
- 堆中某个节点的值总是不大于或不小于其父节点的值
- 堆总是一棵完全二叉树
堆的定义如下:n 个元素的序列 {K1,K2,Ki,…,Kn} 当且仅当满足下关系时,称之为堆:
(Ki <= K2i,ki <= K2i+1)或者(Ki >= K2i,Ki >= K2i+1), (i = 1,2,3,4...n/2)- 若将和此次序列对应的一维数组(即以一维数组作此序列的存储结构)看成是一个完全二叉树,则堆的含义表明:完全二叉树中所有非终端结点的值均不大于(或不小于)其左、右孩子结点的值。由此,若序列
{K1,K2,…,Kn}是堆,则堆顶元素(或完全二叉树的根)必为序列中n个元素的最小值(或最大值)
将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
堆有序:当一颗二叉树的每个节点都大于等于它的两个子节点时,称为堆有序。
常见的堆有:二叉堆、二项堆、斐波那契堆。本文重点介绍二叉堆。
二叉堆
二叉堆 binary heap 是一种特殊的堆。二叉堆是:完全二叉树或者是近似完全二叉树。二叉堆有两种:
- 最大堆
父结点的键值总是大于或等于任何一个子节点的键值。 - 最小堆
父结点的键值总是小于或等于任何一个子节点的键值。
二叉堆定义:一组能够用堆有序的完全二叉树排序的元素,并在数组中按照层级存储(不使用数组的第一个位置)。
二叉堆在数组中的数学性质:
- 位置为
k的节点,其父节点位置为向下取整[k/2],其两个子节点位置为2k,2k+1 - 位置为
k的节点,在数组中向上移动一层时,则令k=2/k;向下移动一层,则令k=2k或者k=2k+1
本文中,默认堆数组的第 0 个元素不保留任何信息,从第 1 个元素开始存储堆元素。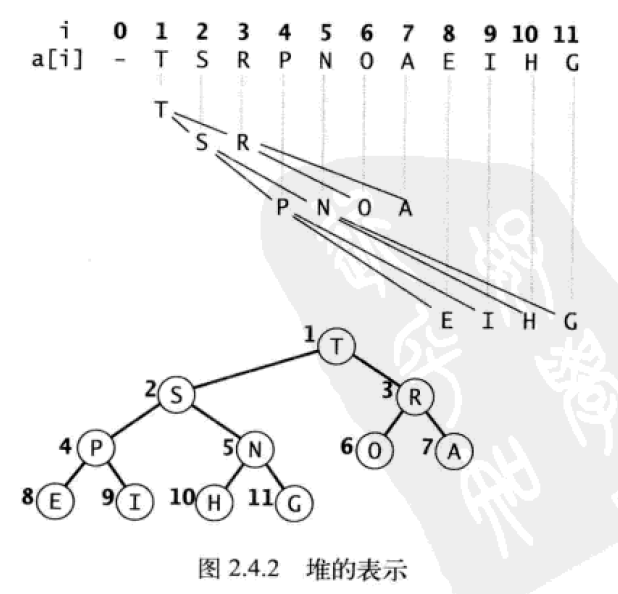
二叉堆有序化
二叉堆的插入和删除操作会打破堆的状态,需要遍历整个堆并按照要求将堆的状态恢复,称为堆的有序化。
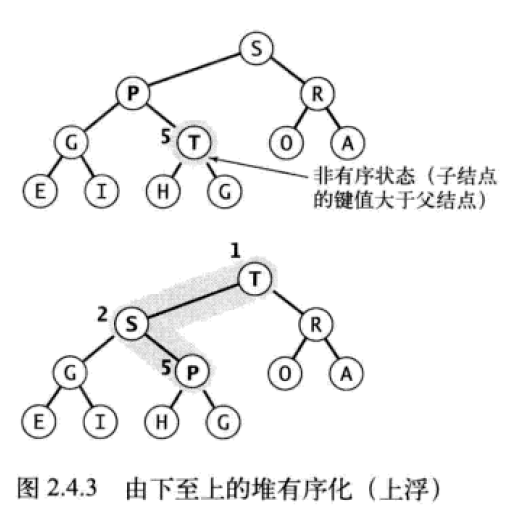
上浮
上浮 swim :由下至上的堆有序化。如果堆的有序状态因为某个节点变得比它的父节点更大而打破,那么需要交换它和它的父节点来修复堆。但是交换后,该节点可能仍然比父节点大,因此需要重复比较,将这个节点不断的上移,直到找到更大的父节点。这个节点每次都需要上浮到堆的上一层,直到堆恢复有序状态。
1 | private void swim(int k) { |
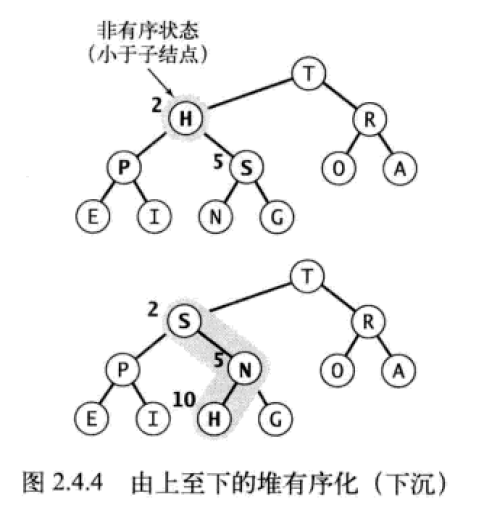
下沉
下沉 sink :由上至下的堆有序化。如果堆的有序状态因为某个节点变得比它的两个子节点或者其中一个子节点更小而打破,那么需要交换它和较大子节点来修复堆。同样,交换后该节点可能仍然比子节点或者其中一个子节点小,因此需要重复比较,将这个节点不断的下移,直到找到它的子节点都比它小或者堆的底部。这个节点每次都需要下沉到堆的下一层,直到堆恢复有序状态。
1 | private void sink(int k) { |
插入和删除最大元素
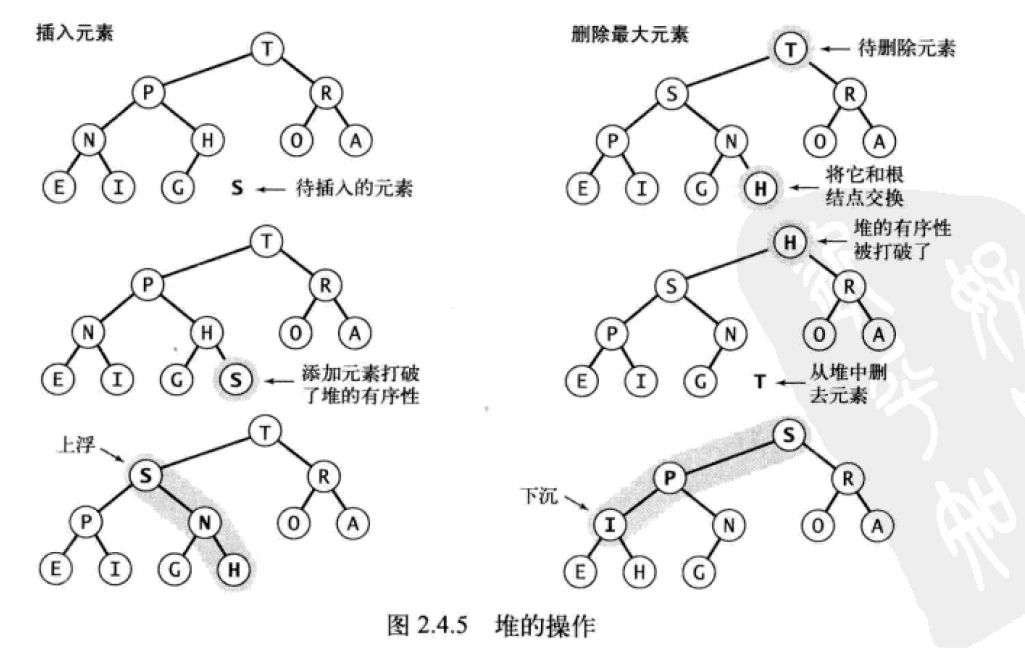
- 插入元素
将新元素加入到数组末尾,并让这个新元素上浮到合适位置。 - 删除最大元素
从数组顶端删除最大元素(根元素),将数组的最后一个元素放到顶端,并将这个元素下沉到合适位置。
1 | public void insert(Key x) { |
根据上面算法的估算,插入和删除最大元素的时间复杂度都是 O(logN)。
二叉堆构造过程
二叉堆的构造过程:逐个插入元素,保持堆的有序状态。
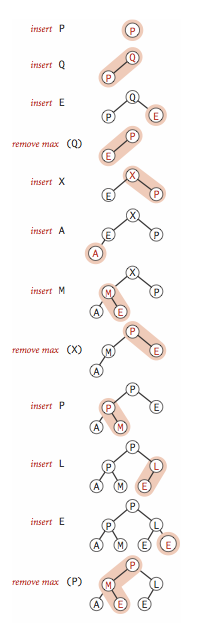
小结
可以看出,优先队列在插入元素的过程中,堆始终保持有序状态;删除最大值(最小值),堆仍然有序。优先队列的特点,不需要事先将所有元素读入内存,可以一边读入,一边保持堆有序状态。
索引优先队列
意义
索引优先队列,首先是一个优先队列,但是又带有索引。索引是用来干什么的呢?我们先回顾下上面介绍的优先队列中,Key[] pq 保存了所有元素,并构成二叉堆,并不方便查找指定元素的位置,或者在指定位置更新元素。索引优先队列,使用数组 Key[] keys 存储元素信息(或其他重要信息),增加一个整型数组 int[] pq 来保存元素下标(即索引),使用索引数组构成二叉堆。这样二叉堆在插入,删除,修改时,仅仅改变的是索引数组,而元素数组并不需要变化(删除元素时置空)。通过索引可以找到元素在堆中的下标,再用这个下标就能访问到元素。
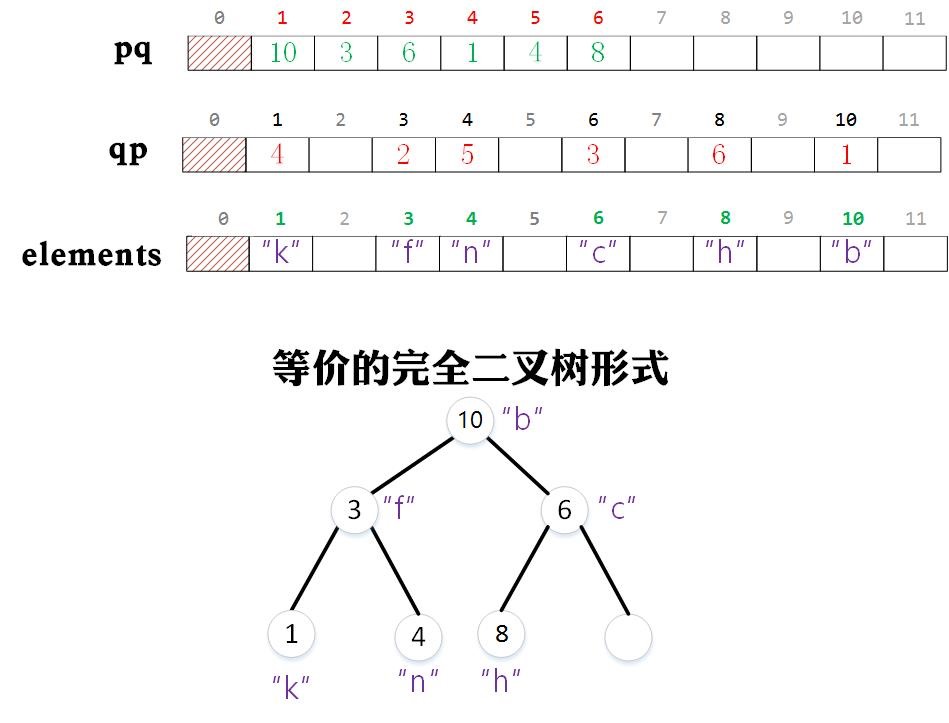
通用 API
1 | public class IndexMinPQ<Key extends Comparable<Key>> |
关键算法
1 | // 插入元素 |
小结
- 时间复杂度
索引优先队列,不管是插入、删除、修改等,时间复杂度都能控制在logN,但是需要辅助数组来快速实现。 - 优点
除了能多保存元素信息,索引优先队列还可以更新指定索引的key值,这个是普通优先队列无法做到的。通常普通优先队列,对外API只包含队列的基本操作,只是在取出元素时,确保每次都是取出的最小值或者最大值。
堆排序
定义
堆排序 Heap sort:使用堆数据结构设计的一种排序算法,它是选择排序的一种。利用小根堆或者大根堆的特性,每次选出最小值或者最大值来完成排序。堆排序有两个阶段:
- 堆构造阶段
将数据读入后,构造一个堆。堆的特点是,不管什么时候加入新数据,堆都是有序的。 - 堆下沉阶段(大根堆,由大到小排序)
始终从堆中取出最大元素,并得到排序结果。取出最大元素后,堆最后一列元素交换到堆顶,并下沉到合适位置,确保堆保持有序。
动图演示
堆构造-插入法
向优先队列一样,逐个插入新元素来构造堆,这个过程时间复杂度为NlogN。
堆构造-原地构造(经典算法)
现有数组为元素读入顺序,直接在这个数组上构造堆。具体方法:从数组中间位置,从右向左逐个元素sink来构造堆,时间复杂度为N。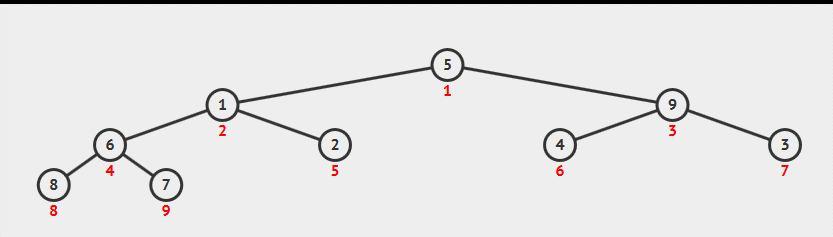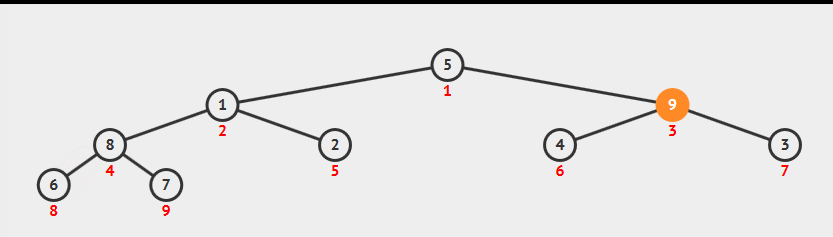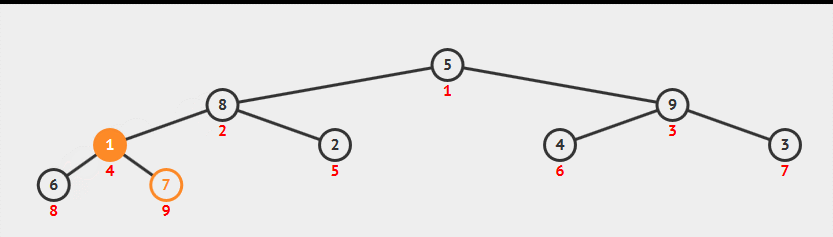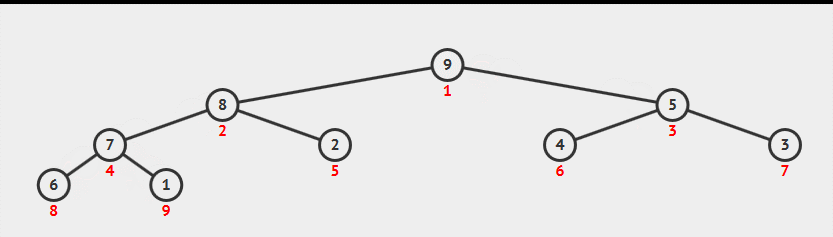
堆取出最大值
优先队列,逐个取出最大值,实现排序效果。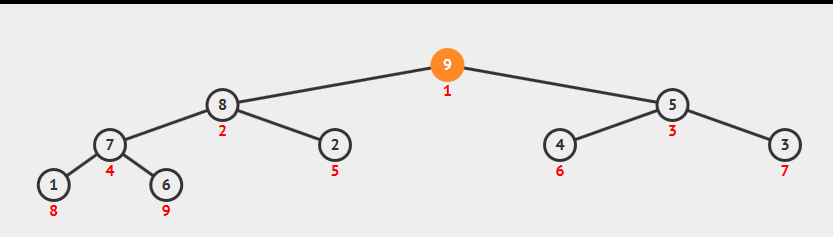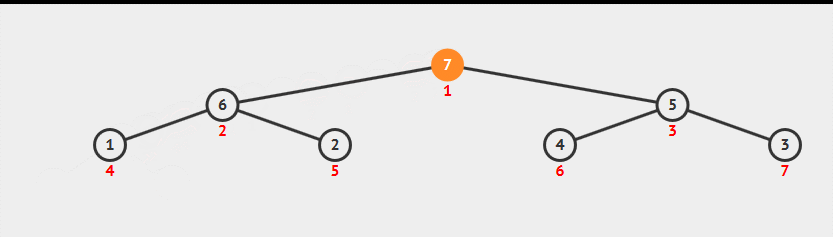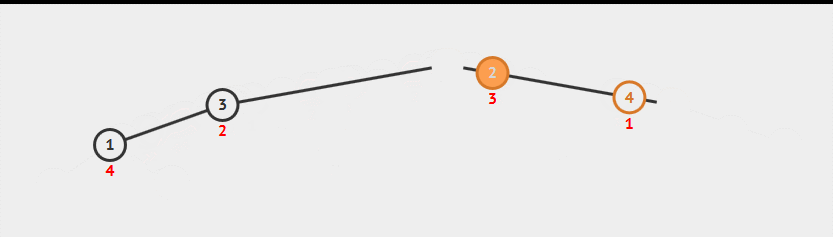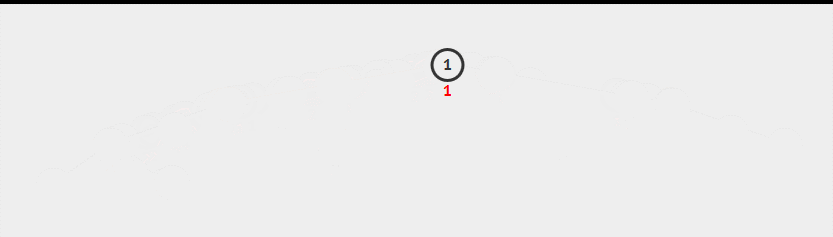
堆排序经典算法代码示例
我们可以使用优先队列,插入元素方法构造堆,删除最大元素方法来实现堆排序。但是我们接下来介绍的是,使用 sink 下沉方法,来原地构造堆和排序,这种算法就是经典的堆排序算法,由 J.W.Williams 发明,并由 R.W.Floyd 在 1964 年改进。
1 | public static void sort(Comparable[] a) { |
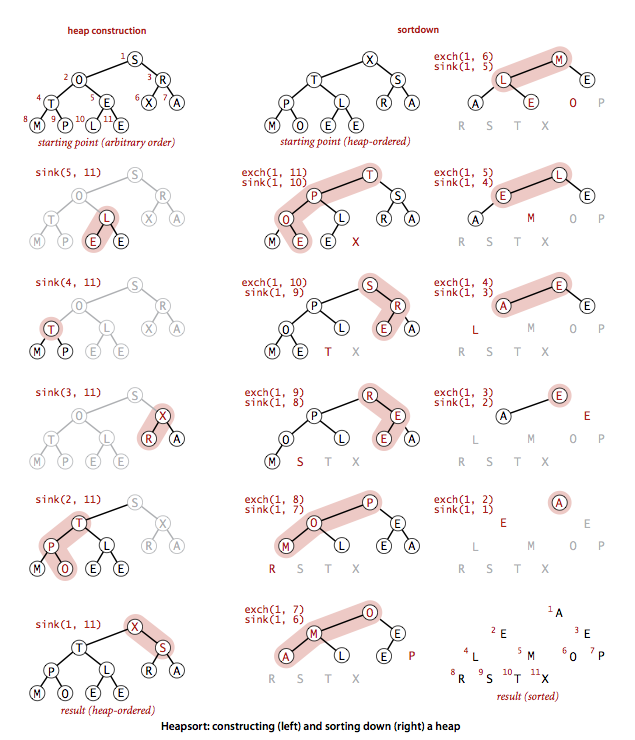
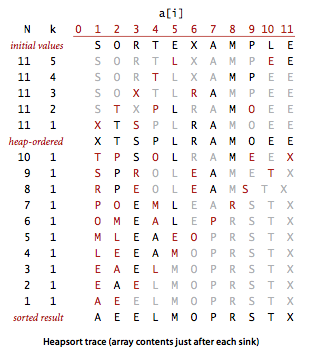
堆排序静态分解图
堆形态分解轨迹
数组形态分解轨迹
特点
经典堆排序算法中:
- 堆构造只需少于
2N次比较和N次交换 - 堆排序只需要
2NlogN次比较和NlogN次交换 - 整个堆排序过程为上述之和
JDK 中的优先队列
JDK 中的优先队列源码为 java.util.PriorityQueue.java,默认是最小优先队列(小根堆),如果需要实现最大优先队列,在构造时传入自定义 Comparator 实现大根堆的比较就可以了。
类图结构
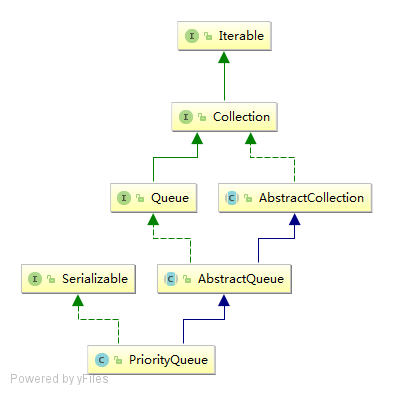
源码分析
1 | public class PriorityQueue<E> extends AbstractQueue<E> |
小结
PriorityQueue 所有公共接口,几乎和队列保持一致。所以可以参考队列的使用方式,但实际的存储是以堆的形式存在的。