算法图的搜索和遍历:广度优先搜索和深度优先搜索。
深度优先搜索
定义
深度优先搜索 DFS: Depth First Search ,基本思路:假设初始状态是图中所有顶点均未被访问,从图中某顶点 v 出发:
- 首先访问该顶点
v,并标记为已访问 - 依次从
v的未被访问的邻接点出发,对图进行深度优先遍历;直至图中和v有路径相通的顶点都被访问 - 若此时图中尚有顶点未被访问,则从一个未被访问的顶点出发,重新进行深度优先遍历,直到图中所有顶点均被访问过为止
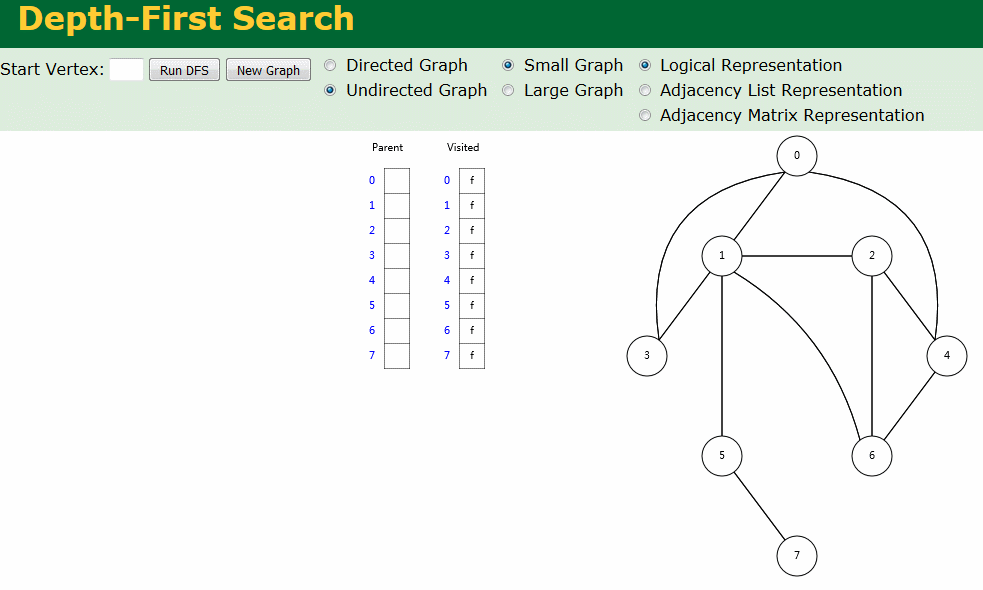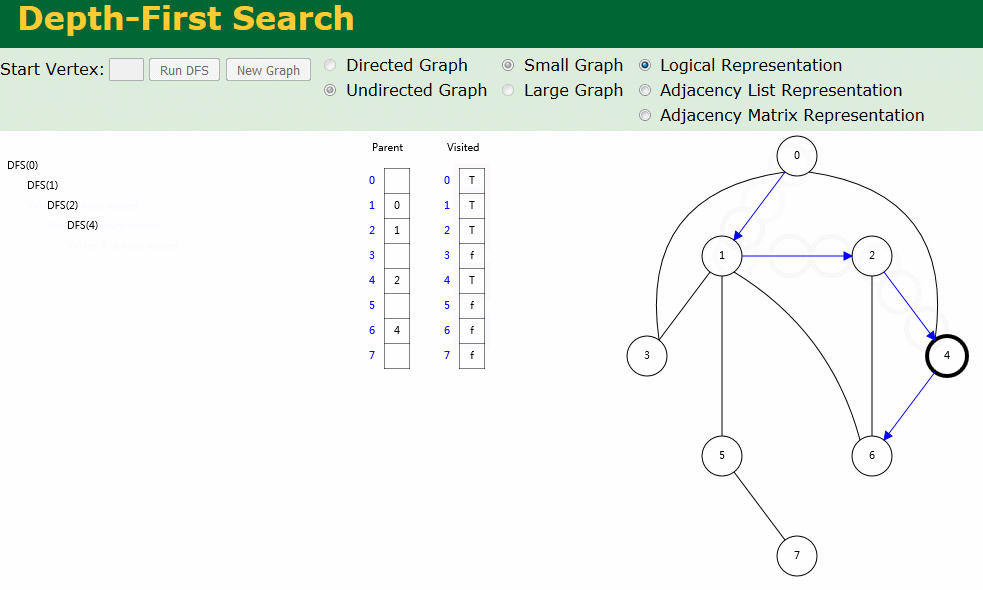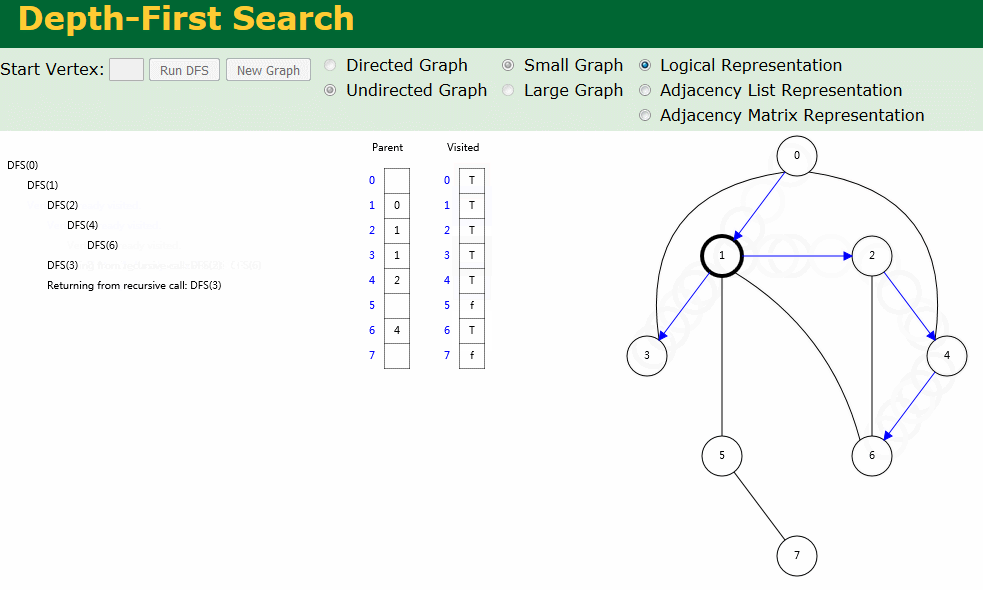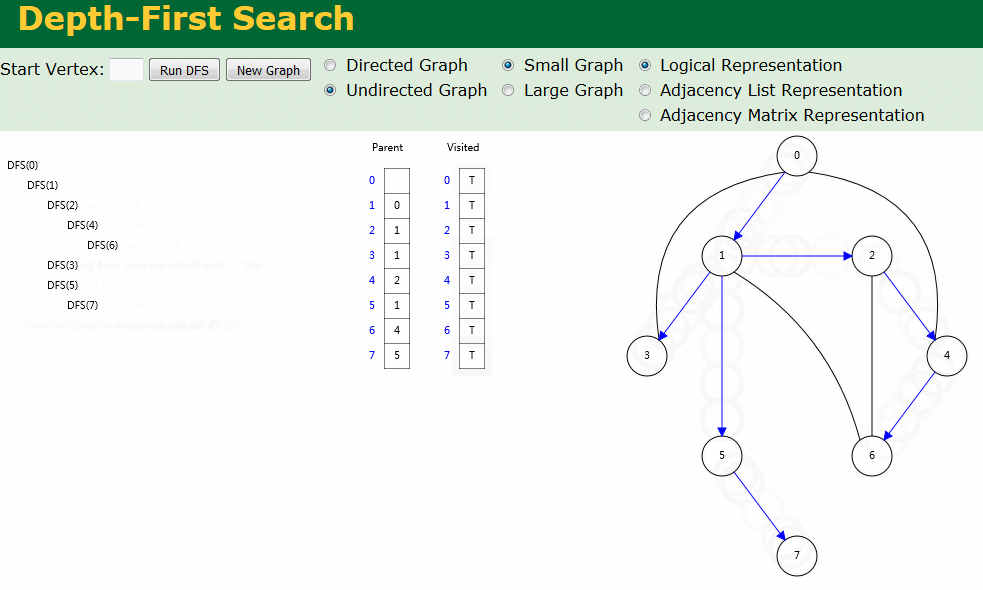
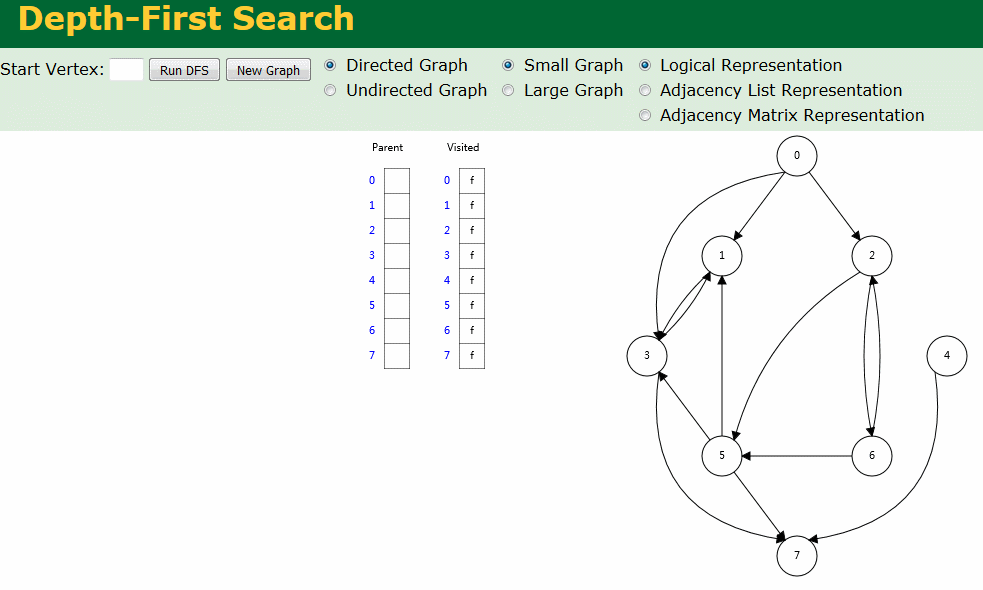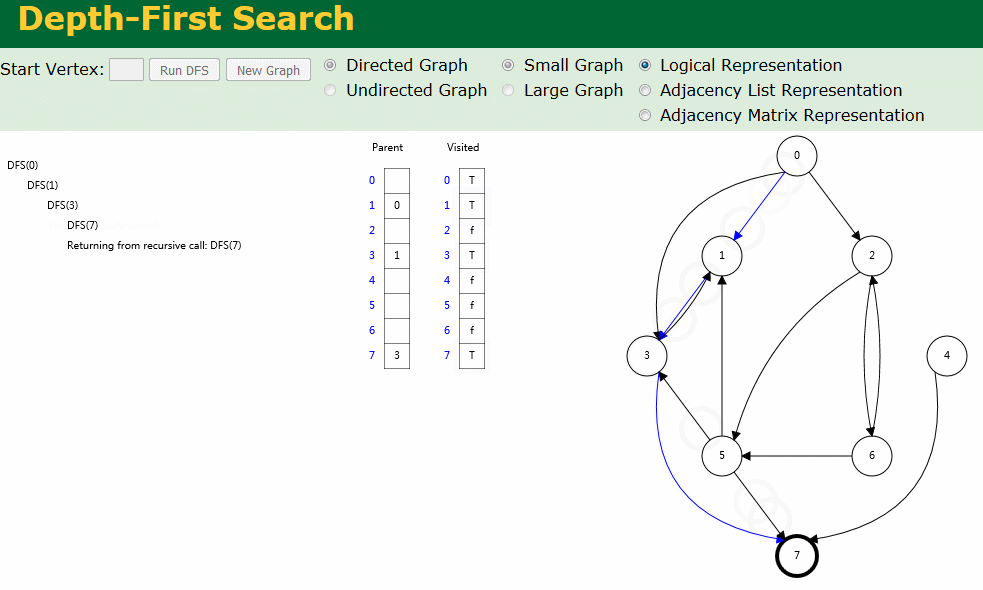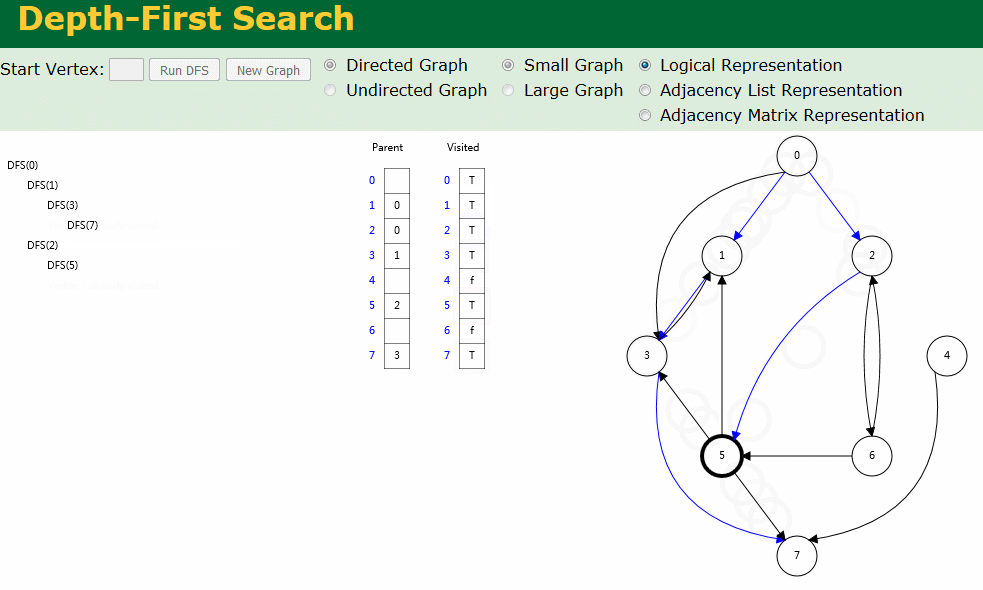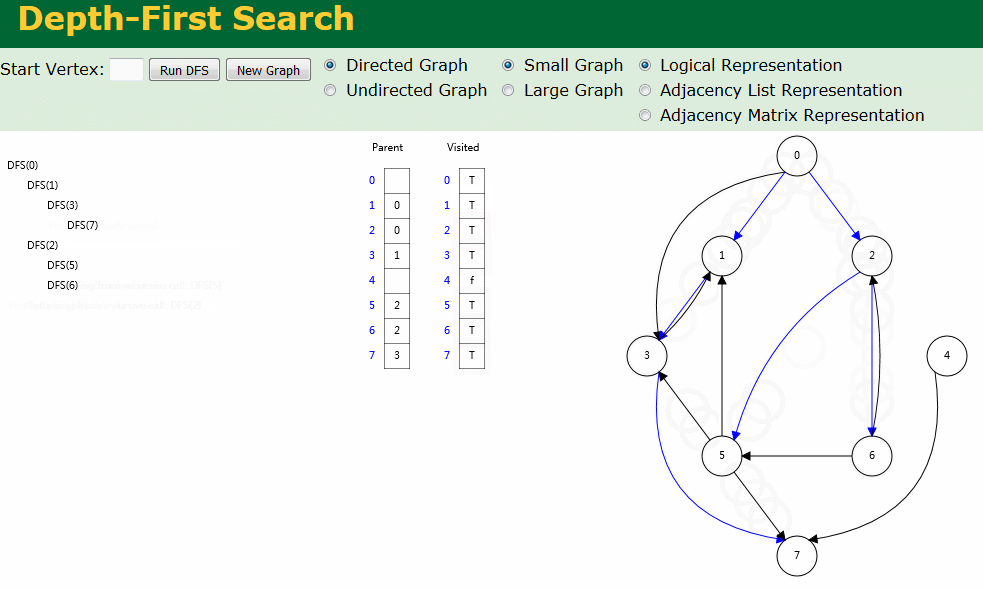
图解
图解中有两个数组:Visited[] 表示是否已被访问;Parent[] 记录图遍历过程父顶点。
- 无向图深度优先搜索
- 有向图深度优先搜索
递归实现
从深度优先搜索的定义可以看出,它是一个标准的递归算法,其算法解析:
marked[]数组
记录当前顶点是否被访问过。parent[]数组
记录当前顶点,在遍历过程中的父节点。G图
代表无向图或者有向图。v顶点
指定深度优先搜索从该顶点触发。G.adj[v]邻接点
顶点v的所有邻接点。
参考:算法 4 的实现
1 | private boolean[] marked; |
非递归实现
adj[]数组
记录每个顶点,对应邻接点的列表。也可以认为它是一个二维数组。stack栈
后进先出,一次记录被访问的轨迹。
参考:算法 4 的实现
1 | private void dfs_non_recur(Graph G, int v){ |
应用场景
- 连通性:给定两个顶点是否连通
- 单点路径:两个给定的顶点是否存在路径
- 检测环:判断图中是否存在环
- 二分图
或者双色问题,是否能用两种颜色将图着色?使得任意一条边的两端都是不同的颜色(即是否为二分图)。 - 单点可达性:有向图中,给定顶点
s到给定顶点v是否可达 - 多点可达性
给定一幅有向图中和顶点集合,是否存在一条从集合中的任意顶点到达给定顶点v的有向路径。多点可达性的一个重要应用场景就是Java垃圾回收中的:标记-清除算法。每个顶点表示一个对象,每条边表示对另一个对象的引用。 - 调度问题
有向图中有优先级限制的调度问题。 - 拓扑排序
- 强连通性
有向图中给定两个顶点是否是强连通的?这幅有向图中有多少个强连通分量?
小结
- 深度优先搜索算法,递归实现简单清晰;在非递归实现中,使用栈来记录访问的节点,后进先出,确保按照深度来搜索
- 算法时间复杂度
O(V+E),其中V是顶点数,E是边数
广度优先搜索
定义
广度优先搜索 BFS: Breadth First Search ,也称为宽度优先搜索;基本思路:假设初始状态是图中所有顶点均未被访问,从图中某顶点 v 出发:
- 首先访问该顶点
v,并标记为已访问 - 依次访问顶点
v的邻接点,并将未被访问的顶点加入队列 - 依次从队列中取出顶点,并按照上一步访问其邻接点,直至队列为空。即先被访问的顶点的邻接点先于后被访问的顶点的邻接点被访问,直到所有已被访问的顶点的邻接点都被访问到
- 如果此时图中尚有顶点未被访问,则需要另选一个未曾被访问过的顶点作为新的起始点,重复上述过程,直至图中所有顶点都被访问到为止
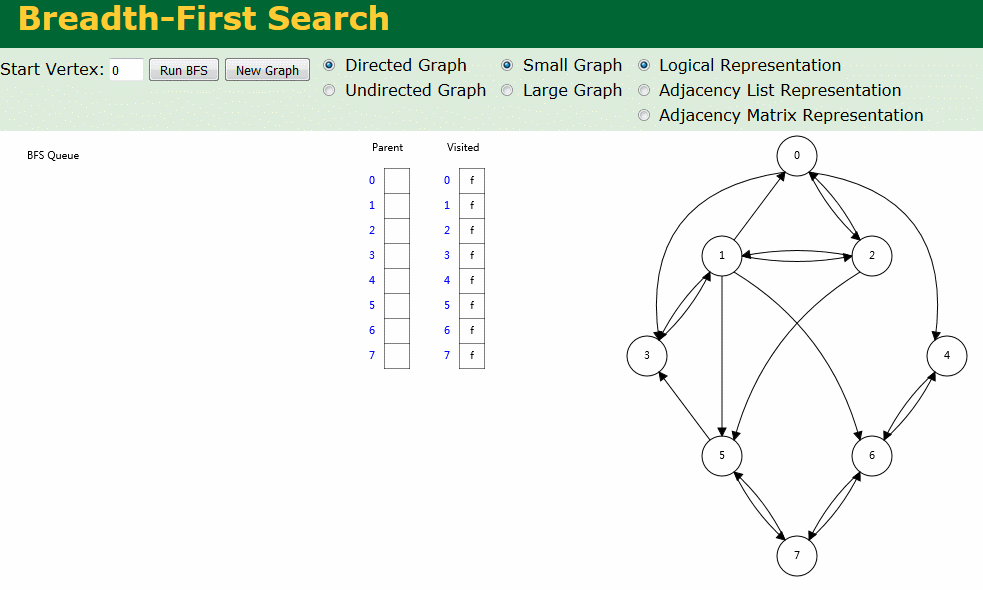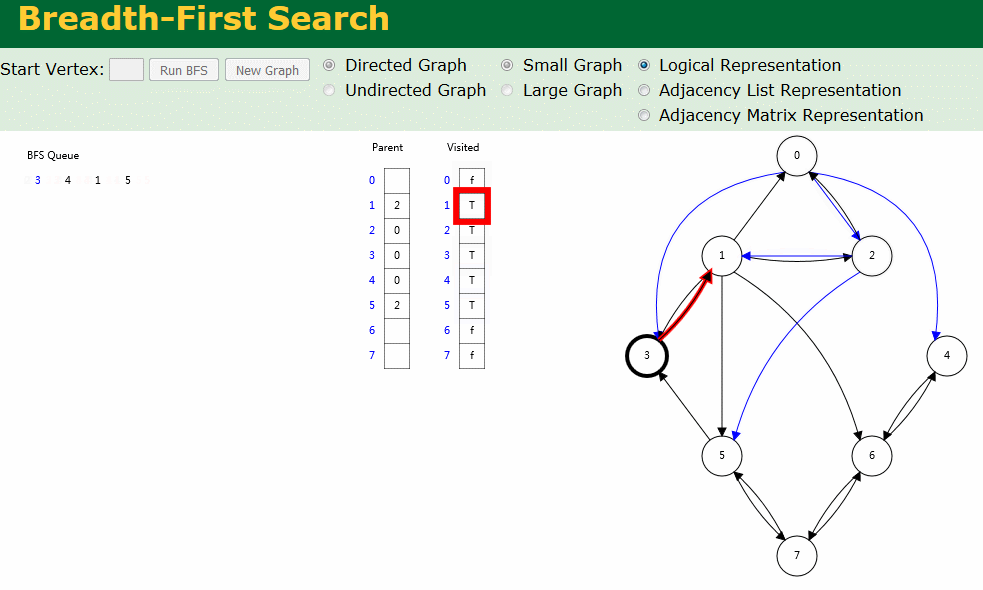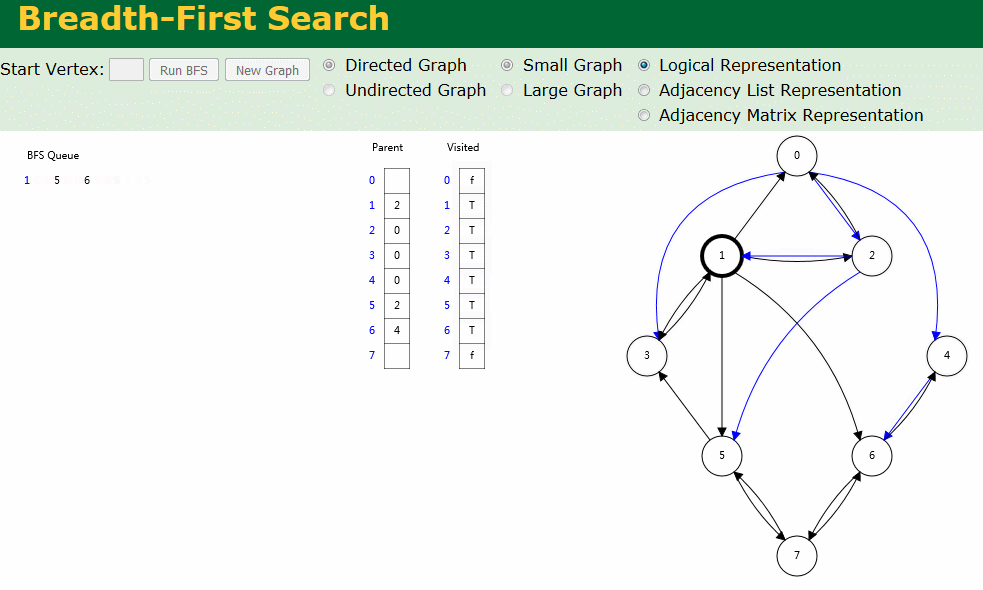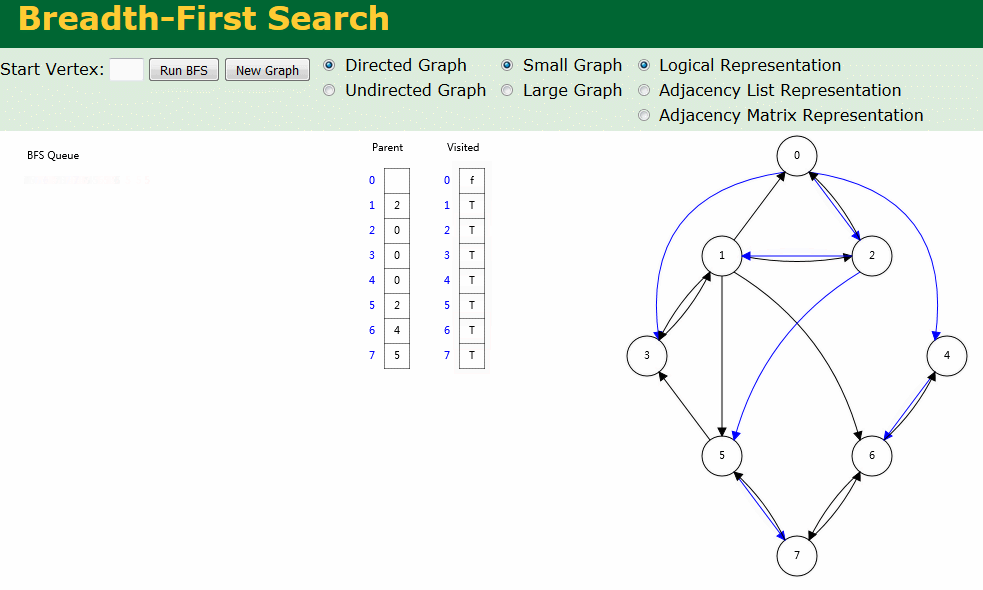
图解
图解中有两个数组:Visited[] 表示是否已被访问;Parent[] 记录图遍历过程父顶点。
- 无向图广度优先搜索
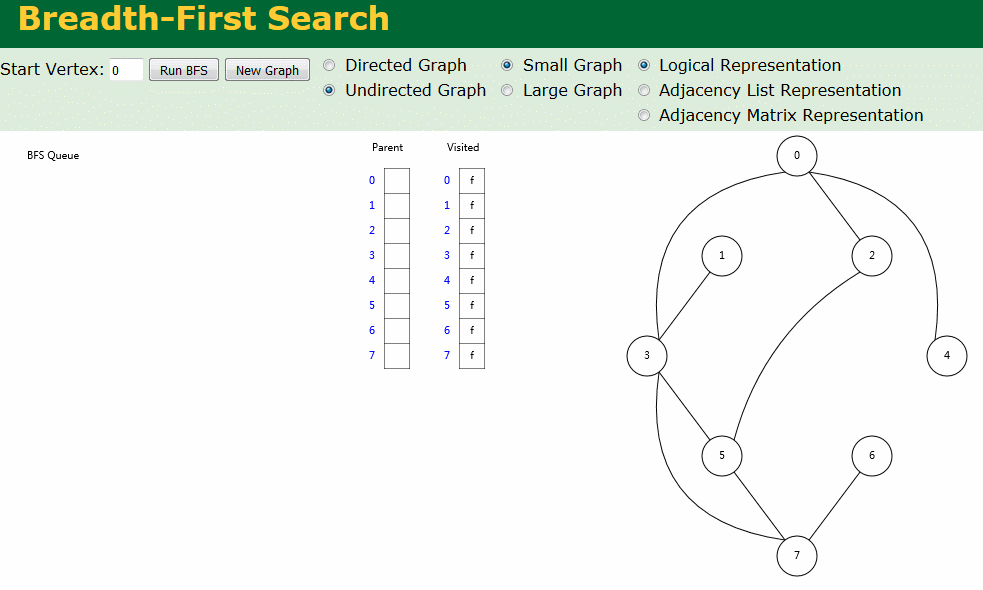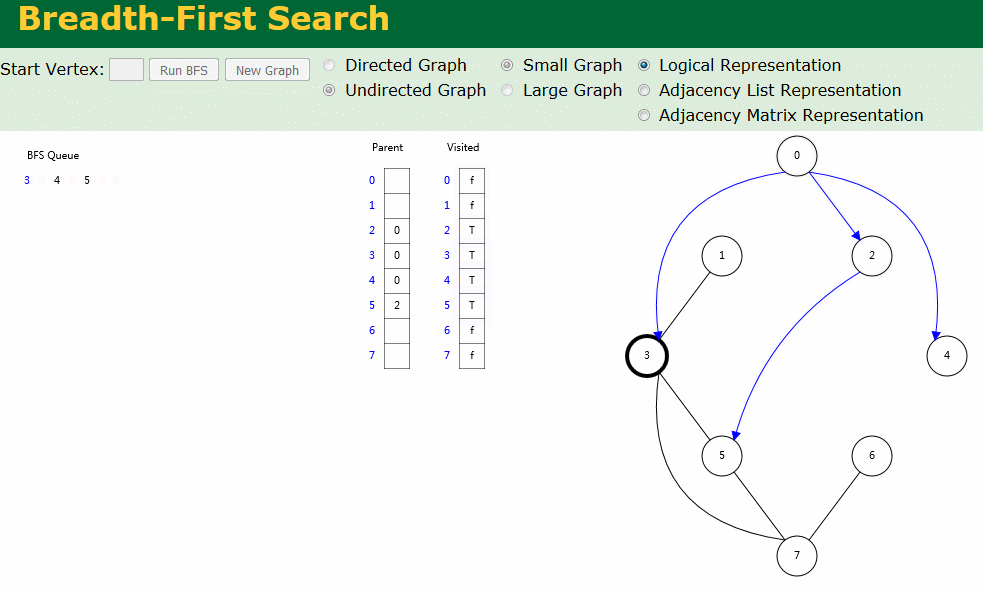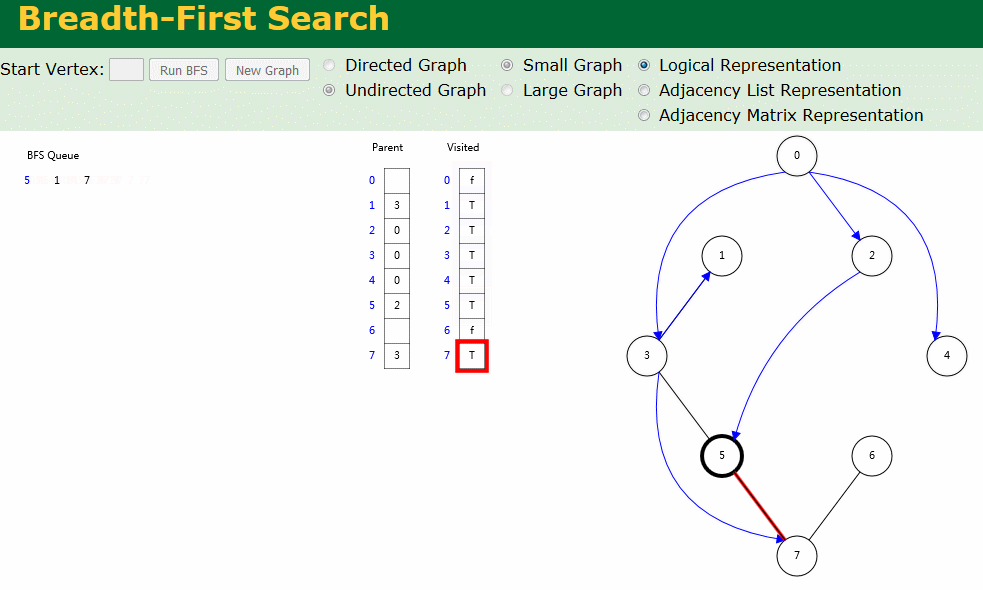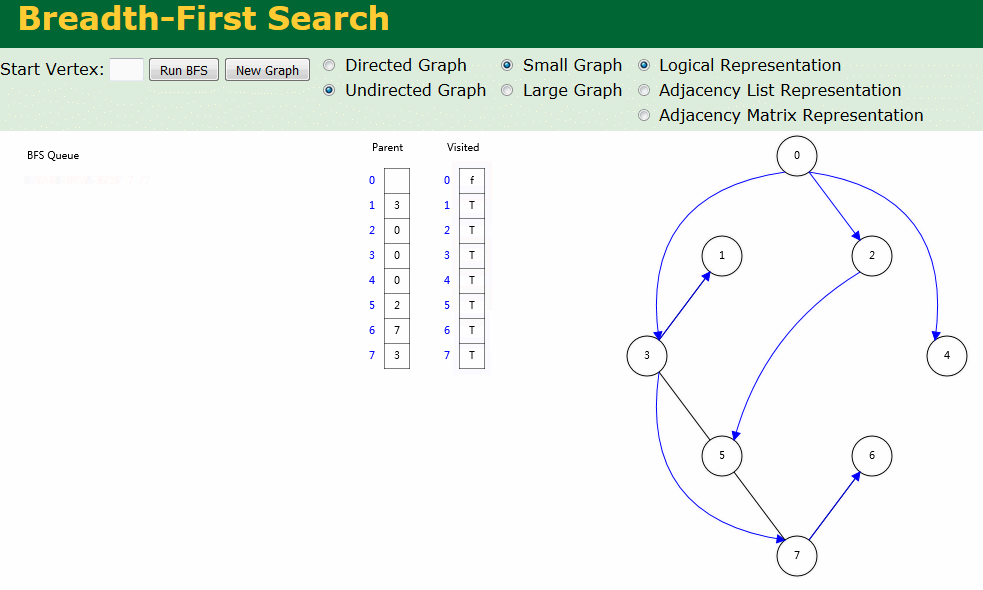
- 有向图广度优先搜索
非递归实现
从广度优先搜索的定义可以看出,算法更适合非递归来实现,其算法解析:
marked[]数组
记录当前顶点是否被访问过。parent[]数组
记录当前顶点,在遍历过程中的父节点。G图
代表无向图或者有向图。v顶点
指定深度优先搜索从该顶点触发。G.adj[v]邻接点
顶点v的所有邻接点。
参考:算法 4 的实现
1 | private boolean[] marked; |
应用场景
广度优先搜索是分层次搜索,
- 单点最短路径:找到给定两个顶点之间的最短路径
- 间隔度数
找到社交网络中间隔度数(或者说熟悉度,几度人脉等)。其实仍然是最短路径问题,计算路径长度。
小结
- 广度优先搜索通常使用非递归实现
- 算法时间复杂度
O(V+E),其中V是顶点数,E是边数
总结
- 深度优先搜索有递归和非递归两种实现方式,广度优先搜索采用非递归实现
- 两种算法的非递归实现中,深度优先搜索使用栈实现,下一个节点从栈顶取出,即最后一个入栈节点;广度优先搜索使用队列实现,下一个节点从队列取出,即第一个入队列节点
- 两种算法时间复杂度相同,都是
O(V+E)
参考文档
- 《算法:第四版》 第 4 章
- 广度优先搜索动画
- 深度优先搜索动画
- 图的遍历动画
- 图的遍历-深度优先搜索和广度优先搜索