Tarjan 算法是 Robert Tarjan (罗伯特·塔扬)发明的,只通过一次深度优先搜索就能计算出有向图的强连通分量,而 Kosaraju 算法需要做两次 DFS 加上计算图的反向图。
算法定义
Tarjan 算法是基于对图深度优先搜索的算法,每个强连通分量为搜索树中的一棵子树。搜索时把当前搜索树中未处理的节点加入一个堆栈,回溯时可以判断栈顶到栈中的节点是否为一个强连通分量。定义两个重要数组:
dfn(v)为顶点v被搜索的次序号low(v)为顶点v被搜索的次序号,或者**v的子树能够追溯到的最早的栈中顶点的次序号**(这句话非常费解,没弄明白!)
本文算法实现及分析的有向图:
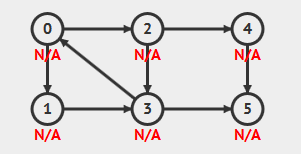
动画演示
visualgo 上动画演示的伪代码是错误的!但是动画实际执行的结果是对的。
算法解析
算法中的几个重要的变量:
marked[]数组
记录当前顶点是否被访问过。stack栈
辅助变量:记录同一个强连通分量中的所有顶点。当DFS第一次访问顶点时,该顶点入栈;当顶点v的强连通分量条件满足时,栈中顶点逐个出栈,直到顶点v也出栈。onStack[]数组
记录当前顶点是否在栈中。dfn[]数组
记录顶点被访问的次序号,dfn[v]=5表示顶点v是第 5 个被访问的顶点。low[]数组low[v]值的计算很复杂,搜索时从顶点v访问顶点w则low[v]=min{low[v], dfn[w]};回溯时顶点v从顶点w回溯,则low[v]=min{low[v], low[w]}。可能帮助理解的概念:
横插边:连接到已经出栈的节点的边;
后向边:连接到已在栈中节点的边;
树枝边:在搜索树中的边。count
强连通分量的个数。
Tarjan 算法涉及到深度优先搜索 DFS 的两个过程:搜索过程和回溯过程。
DFS遍历有向图中所有的顶点,并将顶点压入栈DFS搜索过程中,对于从顶点v访问顶点w:如果顶点w没有被访问过,对w进行DFS遍历;如果w被访问过且w在栈中,更新low[v]的值:low[v]=min{low[v], dfn[w]}DFS回溯过程中,对于顶点v从顶点w回溯,更新low[v]的值:low[v]=min{low[v], low[w]}- 不管是搜索过程还是回溯过程,如果顶点
v满足dfn[v] == low[v],则栈中顶点v之上的顶点是一个强连通分量!栈中元素逐个出栈,直到顶点v出栈
1 | public class TarjanSCC { |
《算法 4》的作者将 low[] 数组做了简化:low[v]=min{low[v], low[u]} ,也没有使用 dfn[] 数组。这样得出的 low[] 结果:同一个强连通分量中所有顶点的 low[] 值相同。本文参考的是 wiki: Tarjan Algorithms 的伪代码,网上大部分实现都是基于这份伪代码。
参考:github tarjanscc 代码
图解
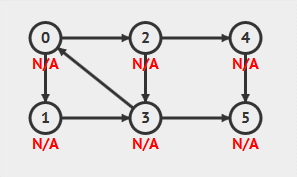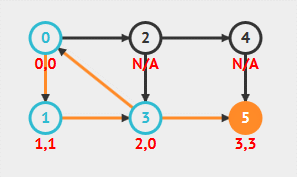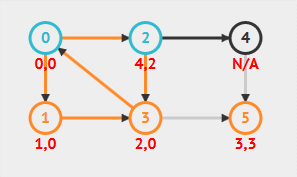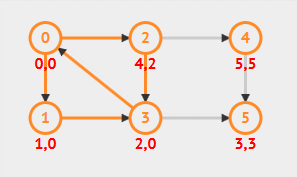
Tarjan 算法的 dfn[] 值很好理解,但是 low[] 并不好理解,特别是代表的含义,本文也没弄明白!!现在通过代码来图解分析 low[v] 的值。深度优先搜索顺序为:0, 1, 3, 5, 2, 4 ,重点分析三个顶点 3, 1, 2。
顶点 3
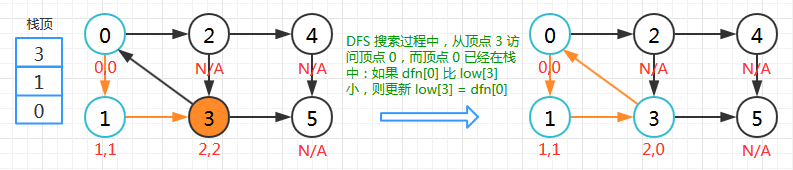
顶点 3 的 low 值是在搜索时变化的,回溯没有更新。DFS 搜索过程中,从顶点 3 访问顶点 0,而顶点 0 已经在栈中:如果 dfn[0] < low[3],则更新 low[3] = dfn[0],所以 low[3]=0 。
顶点 1
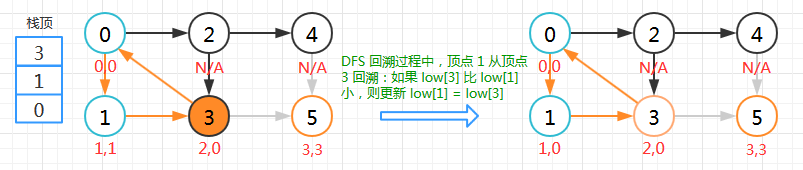
顶点 1 的 low 值是在回溯时更新的,搜索时因为是第一次访问直接赋值次序号。DFS 回溯过程中,顶点 1 从顶点 3 回溯:如果 low[3] < low[1],则更新 low[1] = low[3],所以 low[1]=0 。
顶点 2
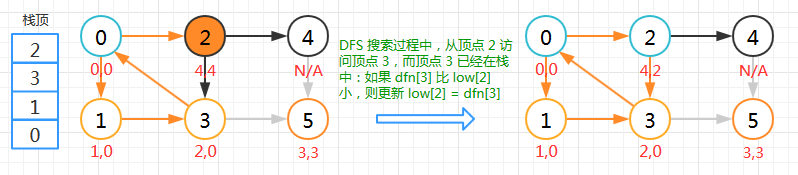
顶点 2 的 low 值是在搜索时变化的,回溯没有更新。DFS 搜索过程中,从顶点 2 访问顶点 3,而顶点 3 已经在栈中:如果 dfn[3] < low[2],则更新 low[2] = dfn[3],所以 low[2]=2。low[2] 的值如果按照定义:最早栈中顶点次序号,应该为 0?但是根据算法实现思路推算,以及实际调试的结果: low[2]=2 。这也是为什么没弄明白 low 值含义的原因!
小结
- 复杂度
Tarjan算法的时间复杂度也为O(V+E),虽然比Kosaraju算法计算量小,但是并没有Kosaraju算法容易理解。 - 强连通
示例中顶点 1 3 4 和 顶点 1 2 4 都是强连通图,但是只有 1 2 3 4 才是强连通分量(相互连通顶点的最大子集)。