介绍子字符串匹配算法:从右至左暴力匹配算法,BM 算法。
从右至左暴力匹配算法
算法实现
使用下标 j 记录文本位置;使用下标 i 记录模式位置。从模式最右边的字符开始比较,从右向左直到整个模式匹配,则返回文本位置。
1 | private int bruteForce(String pattern, String text){ |
时间复杂度
暴力匹配算法在长度为 N 的文本中查找长度为 M 的模式,时间复杂度为 O(NM) 。
BM 算法基础概念
BM: Boyer-Moore 算法:大部分文本编辑器的查找功能 CTRL+F ,都是使用的该算法。KMP 算法中,模式和文本同时向右移动,文本逐个字符向后移动(不回退),模式从左向右逐个字符去匹配,当出现不匹配时,模式可以利用已知信息向前跳跃式继续匹配。而 BM 算法中,文本跳跃式向后移动,模式从右向左逐个字符匹配(这会变相导致文本出现回退),当出现字符不匹配时,利用模式的已知信息,文本可以直接大范围跳跃式向后移动,这也是算法更高效的原因。BM 算法中计算的是文本的移动距离,它会依据坏字符和好字符规则来决定;而 KMP 算法计算的是模式的移动距离。
坏字符规则
坏字符 bad character:模式与文本匹配过程中,文本出现的第一个不匹配字符。也就是坏字符是文本中的字符。

示例中:S 即为坏字符,不匹配的字符。
坏字符规则移动位数
移动位数:坏字符位置 - 模式中上一次出现的位置
位置是从 0 开始编号的;如果坏字符不在模式中,则上次出现位置为 -1 。
- 坏字符不在模式中
文本向右移动位数:坏字符及前面字符串的长度;即坏字符所在位置加上 1 。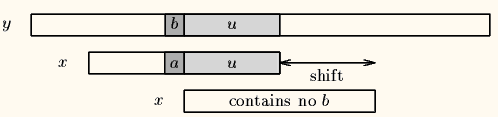
- 坏字符在模式中
文本向右移动位数:坏字符位置 - 模式中上一次出现的位置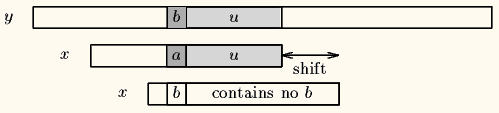
- 示例
模式从尾部开始和文本比较:文本中P与模式最后一个字符E不匹配,坏字符P的位置为 6 ,而它在模式中上一次出现的位置为 4 ,所以坏字符规则移动位数为:6-4=2 。
好后缀规则
好后缀 good suffix:模式与文本匹配过程中,模式已经与文本相匹配了的字符串。也就是模式中所有尾部匹配的字符串。

示例中:模式尾部匹配的字符串为 MPLE, PLE, LE, E,它们都是好后缀,而 MPLE 为最长好后缀。
好后缀规则移动位数
好后缀匹配有三种情况:
case1模式串中有子串和最长好后缀完全匹配,则将最靠右的那个子串(最长好后缀在模式中上一次出现位置的子串)移动到好后缀的位置继续进行匹配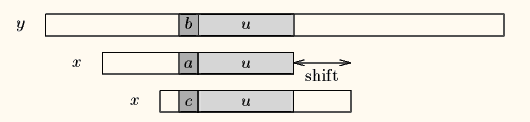
case2如果不存在和最长好后缀完全匹配的子串,则在好后缀中找到pattern[m-1-s…m-1]=pattern[0…s]尽量长并匹配的子串,也就是从模式第一个字符开始匹配的子串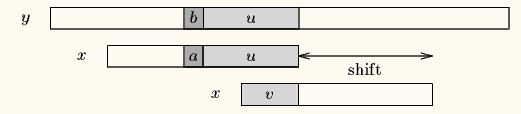
case3如果完全不存在和好后缀匹配的子串,则右移模式长度的距离
移动位数:好后缀位置 - 模式中上一次出现的位置
- 好后缀的位置
以最后一个字符位置为准。也就是说,好后缀位置其实始终为m-1,m为模式长度。 - 模式中上一次出现的位置
根据上面三种匹配规则:当存在和最长好后缀完全匹配的子串时,上一次出现位置为子串位置;当好后缀只有部分子串匹配时,需要找到从头部开始匹配的尽量长的好后缀子串,上一次出现位置为该子串的位置;如果不存在和好后缀匹配的子串,上一次出现位置为 -1 。
因为模式是从右向左匹配的,所以这里说的子串位置,指的是子串最右边字符的位置。 - 示例
上面好后缀规则示例中MPLE, PLE, LE, E都是好后缀,以最后一个字符E为准,好后缀位置为 6 。因为好后缀只有部分子串匹配,从头部开始匹配尽量长的好后缀子串为E,它在模式中上一次出现的位置为 0 ,所以好后缀规则移动位数为 6-0=6 。
文本移动位数
BM 算法的基本思想,文本的最终移动位置为两个规则移动位数的最大值。
文本移动位数 =
Max{坏字符规则移动位数,好后缀规则移动位数}。
图解
示例文本:HERE IS A SIMPLE EXAMPLE;模式 EXAMPLE 。

BM 算法解析
坏字符距离数组 bmBc[]
数组相关信息:
- 数组长度
通常以 8 位字符也就是 256 位长度来表示所有字符,也就是ASCII能表示的字符;如果是模式中存在中文,需要使用 16 为字符也就是 65536 位长度来表示。大部分算法中都取的是 256 (可能因为算法主要针对的是英文吧?)。 - 下标
以字符作为下标,而不是位置。这就是为什么要用 256 来表示数组长度了,数组可以包含所有的ASCII字符。 - 含义
bmBc['v']表示字符v在模式中最后一次出现的位置,距离模式尾部的长度。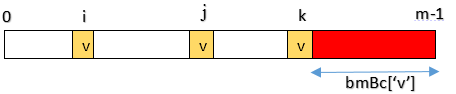
在坏字符规则中,对应两种情况,我们分别计算对应的坏字符数组:
- 坏字符没有出现在模式中
这种情况很简单,坏字符在模式中上一次出现的位置为 -1,所以距离模式尾部为模式的长度:bmBc['v'] = pattern.length()。 - 坏字符出现在模式中
如果坏字符上一次出现的位置为i,那么坏字符距离模式尾部的距离为:bmBc['v'] = pattern.length()-i-1。
坏字符规则移动位数
坏字符数组 bmBc[] 表示:坏字符最后一次出现位置距离模式尾部的长度。我们根据这个长度来计算坏字符规则中,模式的移动位数:
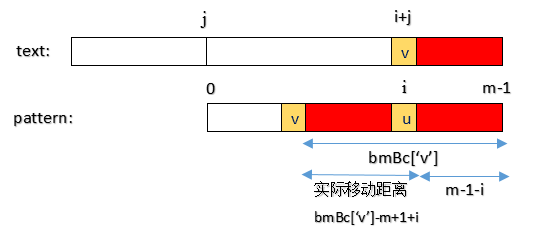
模式在第 i 个位置的字符 u,和文本在第 i+j 个位置的字符 v 不匹配,坏字符为 v。坏字符在模式中上一次出现,距离模式尾部的距离为 bmBc['v'],所以坏字符在模式中上一次出现的位置为 m-1-bmBc['v']。
套用公式:模式实际移动位数 = 坏字符位置 - 模式中上一次出现的位置。模式实际移动位数为 i - (m-1-bmBc['v']),即 bmBc['v']-m+1+i 。
好后缀长度数组 suffix[]
好后缀长度数组 suffix[] 长度等于模式的长度,它的下标就是位置。模式以最后一个字符为准,对应的所有后缀中,suffix[i] 表示以 i 位置结束的子串,其所有后缀中和模式所有后缀的最长共有元素长度。
根据以上定义,假设模式为 bcababab ,它对应的所有后缀为 bcababab, cababab, ababab, babab, abab, bab, ab, b ,从右向左计算模式的每个子串的所有后缀和模式所有后缀的最长共有元素长度:
| 模式的子串 | 子串的所有后缀 | 最长共有元素 | 长度 |
|---|---|---|---|
| bcababab | bcababab, cababab, ababab, babab, abab, bab, ab, b | bcababab | 8 |
| bcababa | bcababa, cababa, ababa, baba, aba, ba, a | 无 | 0 |
| bcabab | bcabab, cabab, abab, bab, ab, b | abab | 4 |
| bcaba | bcaba, caba, aba, ba, a | 无 | 0 |
| bcab | bcab, cab, ab, b | ab | 2 |
| bca | bca, ca, a | 无 | 0 |
| bc | bc, c | 无 | 0 |
| b | b | b | 1 |
有了以上定义和示例说明,通过算法来计算 suffix[] 数组,假设:
i是当前位置,计算suffix[i]的值f是上一轮匹配成功的起始位置g是上一轮匹配的失配位置
这里的匹配指的是 i 位置的子串与模式后缀的匹配。从右向左扫描模式,也就是从后向前计算 suffix[] 数组:
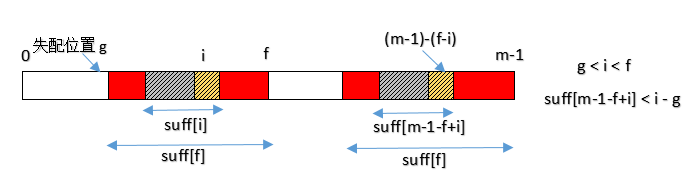
当 g < i < f 时,必定会有 pattern[i]=pattern[m-1-f+i] ;如果 suffix[m-1-f+i] < i-g ,则必定会有 suffix[i] = suffix[m-1-f+i] ,充分利用已经计算过的 suffix 值。
如果是其他情况(即不能利用已知的 suffix 值),也就是说并不是每个位置都能进行成功匹配(实际上能够进行成功匹配的位置并不多)。当在起始位置就不匹配时,可以假定 f=g=i ,直接逐个字符比较计算 suffix 值。
好后缀移位数组 bmGs[]
好后缀移位数组 bmGs[] 长度:等于模式的长度,它的下标就是位置,它的计算需要借助好后缀长度数组 suffix[] 。
case1模式中有子串和最长好后缀完全匹配
位置j出现不匹配,移动位数为bmGs[j]=m-1-i,即bmGs[m-1-suffix[i]]=m-1-i。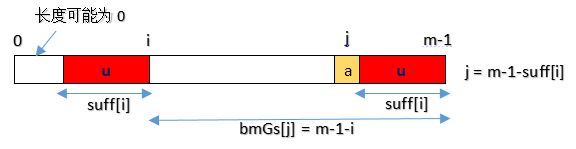
case2模式中没有最长好后缀的子串,则在好后缀中找到pattern[m-1-s…m-1]=pattern[0…s]尽量长并匹配的子串
位置j出现不匹配,当0<=j<m-1-i时,存在suffix[i]=i+1,且移动位数为bmGs[j]=m-1-i。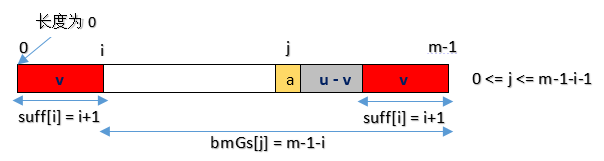
case3完全不存在和好后缀匹配的子串
只要出现不匹配,移动位数为整个模式长度,即bmGs[i]=m。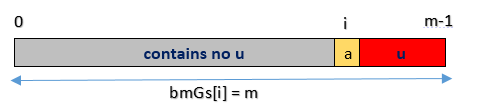
算法实现
1 | public class BoyerMoore { |
参考:algs4: bm 。从算法实现也可以看出,BM 算法和从右向左的暴力算法相比,增加预处理阶段,并且文本大范围向后移动,其他思路基本一致。BM 算法主要是改进了暴力匹配算法中,文本移动的位置;而模式中已经匹配成功的,并没有特别处理,也就是可能出现冗余的匹配计算。
时间复杂度
BM 算法在最坏情况下,和暴力匹配算法一致,时间复杂度为 O(MN);但实际中通常情况下时间复杂度仅需 O(N/M) 。