介绍树的定义和基本术语;二叉树基础知识、性质;二叉树前中后序遍历,层次遍历;哈夫曼编码等。
树的定义和基本术语
树的定义
树 Tree 是 n(n≧0) 个结点的有限集合 T,若 n=0 时称为空树,否则:
- 有且只有一个特殊的称为:树的根
Root结点 - 若
n>1时,其余的结点被分为m(m>0)个互不相交的子集T1, T2, T3, ... , Tm,其中每个子集本身又是一棵树,称其为根的子树Subtree
这是树的递归定义,即用树来定义树,而只有一个结点的树必定仅由根组成。
基本术语
- 结点
node
一个数据元素及其若干指向其子树的分支。 - 结点的度
degree
结点所拥有的子树的棵数称为结点的度。 - 树的度
树中结点度的最大值称为树的度。 - 叶子
leaf结点
树中度为 0 的结点称为叶子结点或终端结点。 - 非叶子结点
度不为 0 的结点称为非叶子结点,或者非终端结点、分支结点;除根结点外,分支结点又称为内部结点。 - 孩子结点
child/ 双亲结点parent
一个结点的子树的根称为该结点的孩子结点或子节点;该结点是其孩子结点的双亲结点或父结点。 - 兄弟结点
同一双亲结点的所有子结点互称为兄弟结点。 - 层次
规定树中根结点的层次为 1 ,其余结点的层次等于其双亲结点的层次加 1 。 - 堂兄弟节点
双亲结点在同一层上的所有结点互称为堂兄弟结点。 - 结点的层次路径
从根结点开始,到达某结点p所经过的所有结点成为结点p的层次路径(有且只有一条)。 - 祖先
ancester/ 子孙descent
结点p的层次路径上的所有结点(p除外)称为p的祖先;以某一结点为根的子树中的任意结点称为该结点的子孙结点。 - 树的深度
depth
树中结点的最大层次值,又称为树的高度。 - 森林
forest
森林是m(m≧0)棵互不相交的树的集合。如果将一棵树的根结点删除,剩余的子树就构成了森林。
二叉树
定义
二叉树 Binary tree 是 n(n≥0) 个结点的有限集合。若 n=0 时称为空树,否则:
- 有且只有一个特殊的称为:树的根
Root结点 - 若
n>1时,其余的结点被分成为二个互不相交的子集T1, T2,分别称之为左子树、右子树,并且左、右子树又都是二叉树
由此可知,二叉树的定义是递归的。
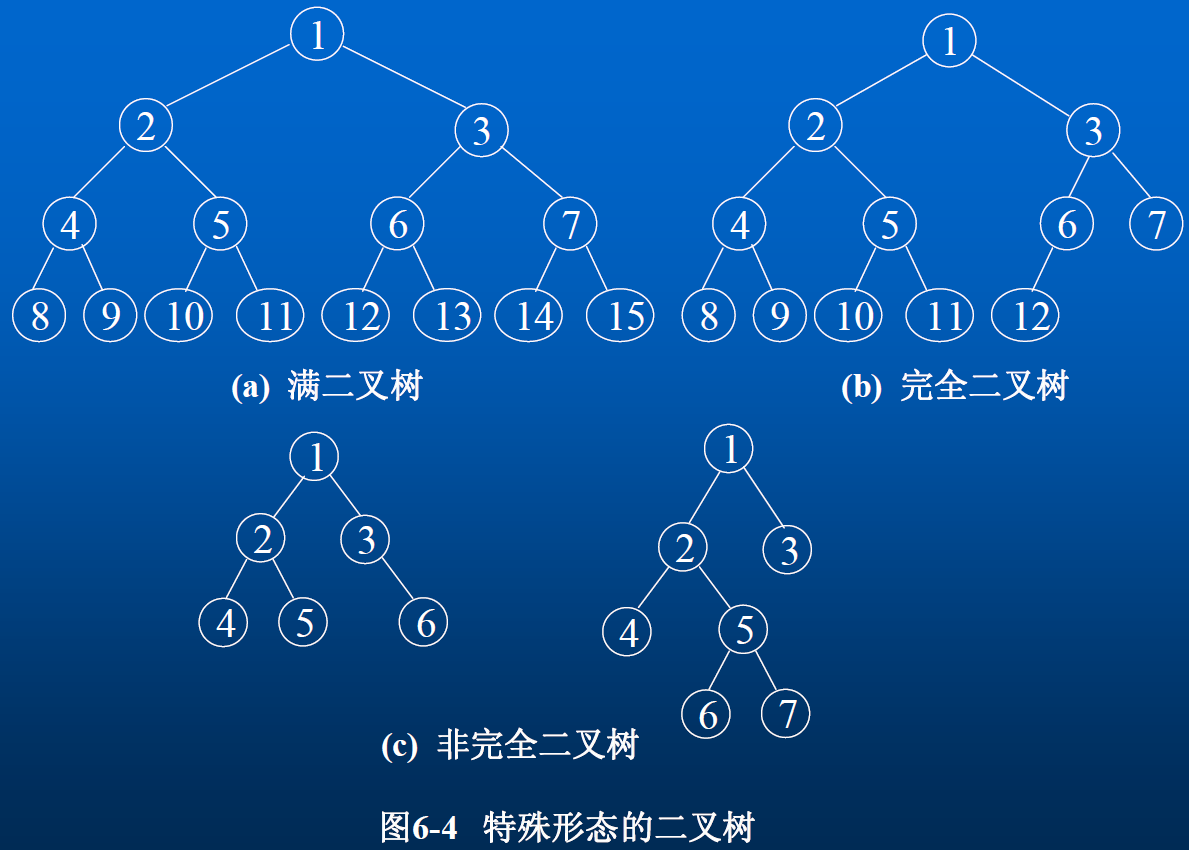
满二叉树
满二叉树 Full Binary Tree :一棵深度为 k 且有 2ᵏ-1 个结点的二叉树称为满二叉树。其特点为:
- 每一层上的结点数总是最大结点数
- 满二叉树的所有的子结点都有左、右子树
- 对满二叉树的结点进行连续编号,若规定从根结点开始,可以按“自上而下、自左至右”的原则进行
完全二叉树
完全二叉树 Complete Binary Tree:如果深度为 k,有 n 个结点的二叉树,当且仅当其每一个结点都与深度为 k 的满二叉树中编号从 1 到 n 的结点一一对应,该二叉树称为完全二叉树。
完全二叉树是满二叉树的一部分,而满二叉树是完全二叉树的特例。其特点为:
- 若完全二叉树的深度为
k,则所有的叶子结点都出现在第k层或k-1层 - 对于任一结点,如果其右子树的最大层次为
k,则其左子树的最大层次为k或k+1
性质
- 在非空二叉树中,第
i(i≧1)层上至多有2^(i-1)个结点 - 深度为
k(k≧1)的二叉树至多有2ᵏ-1个结点 - 对任何一棵二叉树,若其叶子结点数为
n0,度为 2 的结点数为n2,则n0 = n2 + 1 N个结点的完全二叉树深度为|logN| + 1;||表示向下取整
对一棵有 n 个结点的完全二叉树(深度为 |logN|+1) 的结点,从第 1 层到第 |logN|+1 层,按照层序从左向右进行编号,则对于编号为 i(1≦i≦n) 的结点:
- 如果
i=1,则结点i是二叉树的根,无双亲结点;否则如果i>1,则其双亲结点编号是|i/2| - 如果
2i>n,则结点i为叶子结点,无左孩子;否则其左孩子结点编号是2i - 如果
2i+1>n,则结点i无右孩子;否则其右孩子结点编号是2i+1
二叉树遍历
几个简称:节点 N:Node,左子树 L:Left subtree 和右子树 R:Right subtree 。
基本概念
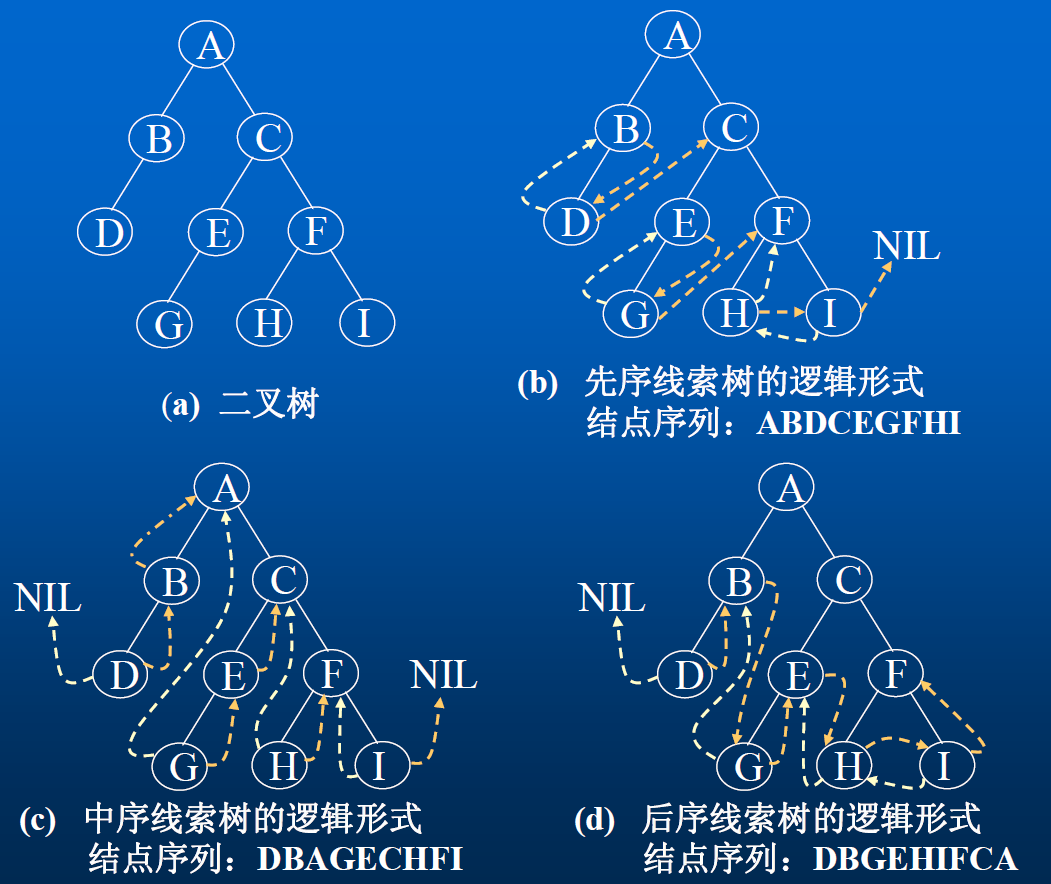
- 前序遍历
前序遍历Preorder Traversal,也称为先序遍历、NLR:先访问根结点,再遍历左子树,然后遍历右子树。 - 中序遍历
中序遍历Inorder Traversal,LNR:先遍历左子树,再访问根,然后遍历右子树。 - 后序遍历
后序遍历Postorder Traversal,LRN:先遍历左子树,再遍历右子树,然后访问根。 - 层级遍历
层次遍历是从根结点开始遍历,按层次次序“自上而下,从左至右”访问树中的各结点。
可以看出:前中后序遍历都是针对根而言的。二叉树也可以按照深度和广度搜索来划分:
- 深度优先搜索
实际就是前序遍历,沿着树的深度遍历树的节点,尽可能深的搜索树的分支;先访问根结点,然后遍历左子树接着是遍历右子树。 - 广度优先搜索
实际就是层级遍历,是从根结点开始沿着树的宽度搜索遍历。
前中后序遍历图解
前中后序遍历递归实现
前序遍历算法的递归定义是:若二叉树为空,则遍历结束;否则:
- 访问根结点
- 先序遍历左子树(递归调用本算法)
- 先序遍历右子树(递归调用本算法)
1 | // 前序遍历 |
从递归算法的实现,也可以看出三种算法的区别仅仅是根访问顺序不一样。
前中后序遍历非递归实现
因为递归算法默认使用的是系统调用栈,而前中后序遍历非递归实现,主要是定义一个栈来替换系统调用栈。
1 | private void preOrderNonRecur(Node node){ |
前序、中序遍历的非递归实现比较简单;后续遍历因为节点无法获取父节点信息,所以需要做多次判断,并记录上次已经被访问的节点。后序遍历的双栈实现巧妙的利用了两个栈的入出栈顺序,获取最终的根左右遍历结果。
非递归算法有多种实现:参考 BinaryTree.Java
层级遍历
层次遍历非递归算法是:若二叉树为空,则返回;否则:
- 访问访问当前节点
- 如果节点左子树不为空,左子树入队
- 如果节点右子树不为空,右子结入队
- 取出队首节点,直到队列为空
1 | private void levelTraversal(Node node){ |
哈夫曼编码
哈夫曼 Huffman 树,又称最优二叉树,是一类带权路径长度最短的二叉树。
基础概念
- 结点路径
从树中一个结点到另一个结点的之间的分支构成这两个结点之间的路径。 - 路径长度
结点路径上的分支数目称为路径长度。 - 树的路径长度
从树根到每一个结点的路径长度之和。 - 结点的带权路径长度
从该结点的到树的根结点之间的路径长度与结点的权值的乘积。权值:各种开销、代价、频度等的抽象称呼。 - 树的带权路径长度
树中所有叶子结点的带权路径长度之和,记做:WPL=W1×L1+W2×L2+...+Wn×ln=ΣWi×Li(i=1,2,...,n),其中:n为叶子结点的个数;Wi为第i个结点的权值;Li为第i个结点的路径长度。
哈夫曼 Huffman 树:具有 n 个叶子结点,每个结点的权值为 Wi 的二叉树不止一棵,但在所有的这些二叉树中,必定存在一棵 WPL 值最小的树,称这棵树为 Huffman 树或称最优树。几个特点:
- 满二叉树不一定是哈夫曼树
- 哈夫曼树中权越大的叶子离根越近
- 具有相同带权结点的哈夫曼树不惟一
- 哈夫曼树的结点的度数为 0 或 2, 没有度为 1 的结点
- 包含
n个叶子结点的哈夫曼树中共有2n – 1个结点 - 包含
n棵树的森林要经过n–1次合并才能形成哈夫曼树,共产生n–1个新结点
示例
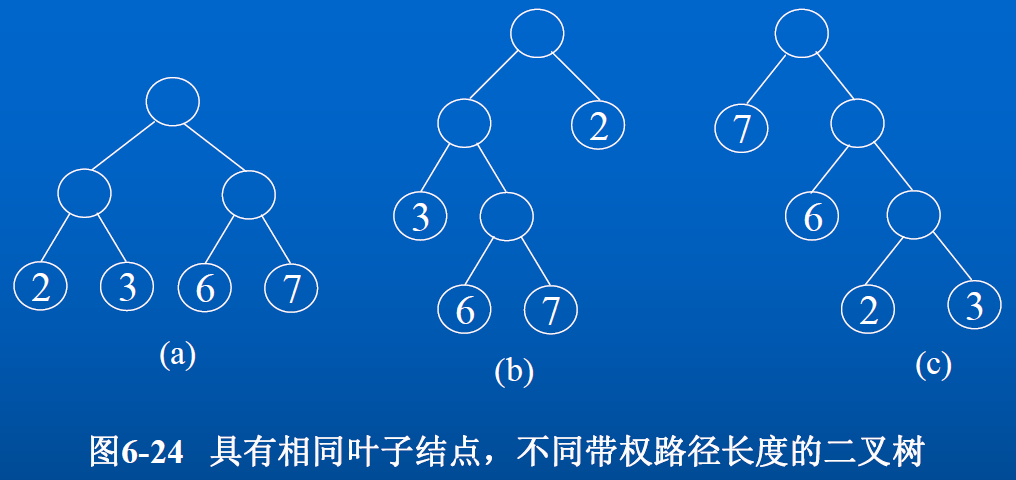
如图所示:权值分别为 22, 33, 66, 77,具有 4 个叶子结点的二叉树,它们的带权路径长度分别为:
a: WPL=2×2+3×2+6×2+7×2=36b: WPL=2×1+3×2+6×3+7×3=47c: WPL=7×1+6×2+2×3+3×3=34
其中图 c 的 WPL 值最小,可以证明它就是 Huffman 树。
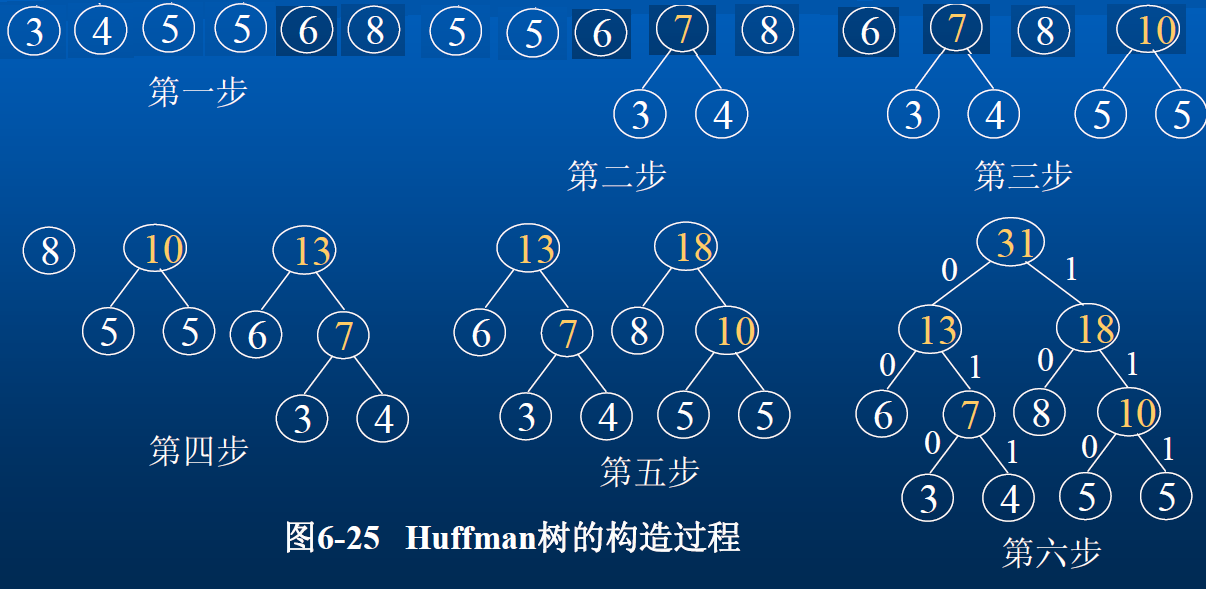
哈夫曼树的构造
根据 n 个权值 {W1, W2, ... , Wn},构造成 n 棵二叉树的集合 F={T1, T2, ..., Tn},其中每棵二叉树只有一个权值为 Wi 的根结点,没有左、右子树;
- 在
F中选取两棵根结点权值最小的树作为左、右子树构造一棵新的二叉树,且新的二叉树根结点权值为其左、右子树根结点的权值之和 - 在
F中删除这两棵树,同时将新得到的树加入F中 - 重复上面两步,直到
F只含一颗树为止
构造 Huffman 树时为了规范,规定 F={T1, T2, ..., Tn} 中权值小的二叉树作为新构造的二叉树的左子树,权值大的二叉树作为新构造的二叉树的右子树;在取值相等时,深度小的二叉树作为新构造的二叉树的左子树,深度大的二叉树作为新构造的二叉树的右子树。
哈夫曼编码
- 前缀编码
在电报收发等数据通讯中,通常需要将传送的文字转换成由二进制字符 0, 1 组成的字符串来传输。为了使收发的速度提高,就要求电文编码要尽可能地短。此外要设计长短不等的编码,还必须保证任意字符的编码都不是另一个字符编码的前缀,这种编码称为前缀编码。Huffman树可以用来构造编码长度不等且译码不产生二义性的编码。 - 哈夫曼编码
设电文中的字符集C={c1, c2, ... , ci, ... , cn},各个字符出现的次数或频度集W={W1, w2, ... , wi, ... , Wn}。以字符集C作为叶子结点,次数或频度集W作为结点的权值来构造Huffman树。规定Huffman树中左分支代表 0 ,右分支代表 1 。从根结点到每个叶子结点所经历的路径分支上的 0 或 1 所组成的字符串,为该结点所对应的编码,称之为Huffman编码。由于每个字符都是叶子结点,不可能出现在根结点到其它字符结点的路径上,所以一个字符的Huffman编码不可能是另一个字符的Huffman编码的前缀。
若字符集 C={a, b, c, d, e, f} 所对应的权值集合为 W={8, 3, 4, 6, 5, 5},如图所示字符 a, b, c, d, e, f 所对应的 Huffman 编码分别是:10, 010, 011, 00, 110, 111。
算法实现
根据哈夫曼树构造定义可以看出,每次选取权值最小的树构造一颗新的树。所以使用优先队列来存储权值,小根堆顶即权值最小。
1 | // Huffman trie node |
参考实现:alg4-Huffman
参考文档
- 数据结构-清华大学严蔚敏 PPT
- 《数据结构与算法分析:C 语言描述》 第 4 章
- wiki: binary tree
- 浅谈数据结构-二叉树
- 二叉树的遍历
- 哈夫曼(huffman)树和哈夫曼编码