Android 图形 Graphic 和显示 Display 是两个独立的部分,这里放在一起简述;介绍了图像和显示相关的基本概念,比如 BufferQueue 生产者消费者模型, Surface/SurfaceFlinger 图形合成等等。
概念
应用开发者可通过两种方式将图像绘制到屏幕上:使用 Canvas 或 OpenGL :
android.graphics.Canvas是一个2D图形API,Canvas API通过一个名为OpenGLRenderer的绘制库实现硬件加速,该绘制库将Canvas运算转换为OpenGL运算,以便它们可以在GPU上执行。从Android 4.0开始,硬件加速的Canvas默认情况下处于启用状态- 除了
Canvas,开发者渲染图形的另一个主要方式是使用OpenGL ES直接渲染到Surface。Android在Android.opengl软件包中提供了OpenGL ES接口
EGL
先熟悉 Android 平台图形处理 API 的标准:
OpenGL
是由SGI公司开发的一套3D图形软件接口标准,由于具有体系结构简单合理、使用方便、与操作平台无关等优点,OpenGL迅速成为3D图形接口的工业标准,并陆续在各种平台上得以实现。OpenGL ES
是由khronos组织根据手持及移动平台的特点,对OpenGL 3D图形API标准进行裁剪定制而形成的。Vulkan
是由khronos组织在 2016 年正式发布的,是OpenGL ES的继任者。API是轻量级、更贴近底层硬件close-to-the-metal的接口,可使GPU驱动软件运用多核与多线程CPU性能。
OpenGL ES 定义了一个渲染图形的 API ,但没有定义窗口系统。为了让它能够适合各种平台,它将与知道如何通过操作系统创建和访问窗口的库结合使用。而在 Android 中,这个库被称为 EGL ;也就是说 EGL 主要是适配系统和关联窗口属性。如果要绘制纹理多边形,应使用 OpenGL ES 调用;如果要在屏幕上进行渲染,应使用 EGL 调用。OpenGL ES 是 Android 绘图 API ,但 OpenGL ES 是平台通用的,在特定设备上使用需要一个中间层做适配, Android 中这个中间层就是 EGL 。
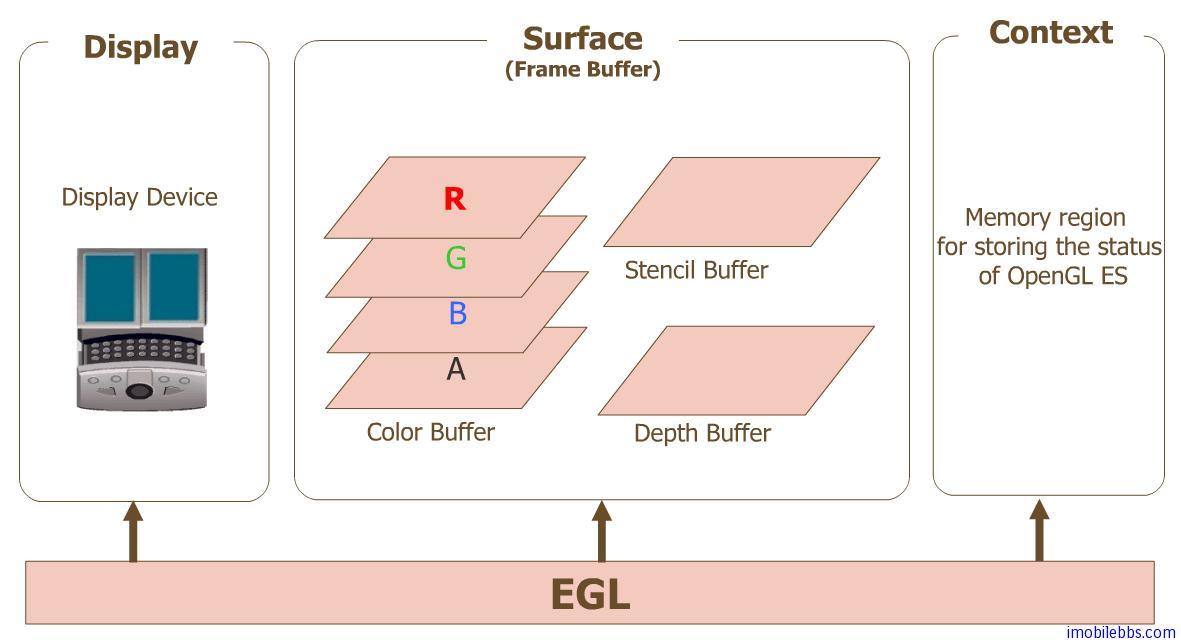
Surface 和 SurfaceFlinger
无论开发者使用什么渲染 API,一切内容都会渲染到 Surface 。 Surface 表示缓冲队列中的生产者,而缓冲队列通常会被 SurfaceFlinger 消耗。在 Android 平台上创建的每个窗口都由 Surface 提供支持。所有被渲染的可见 Surface 都被 SurfaceFlinger 合成到显示部分。它们遵循生产者/消费者模型:
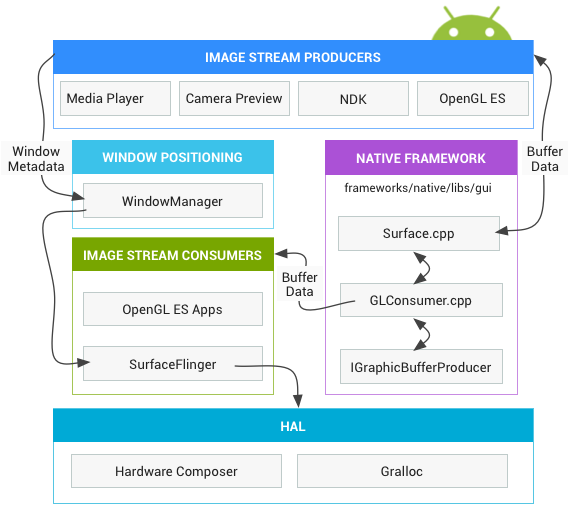
- 图像流生产者
图像流生产者可以是生成图形缓冲区以供消耗的任何内容。例如OpenGL ES, Canvas 2D, mediaserver视频解码器。 - 图像流消费者
图像流的最常见消费者是SurfaceFlinger,该系统服务会消耗当前可见的Surface,并使用窗口管理器中提供的信息将它们合成到显示部分。SurfaceFlinger是可以修改所显示部分内容的唯一服务。SurfaceFlinger使用OpenGL和Hardware Composer来合成一组Surface。
其他OpenGL ES应用也可以消耗图像流,例如相机应用会消耗相机预览图像流。非GL应用也可以是消费者,例如ImageReader类。
WMS: WindowManagerServices
窗口管理器,控制窗口的 Android 系统服务,它是视图容器。窗口总是由 Surface 提供支持。该服务会监督生命周期、输入和聚焦事件、屏幕方向、转换、动画、位置、变形、 Z-Order 以及窗口的其他许多方面。窗口管理器会将所有窗口元数据发送到 SurfaceFlinger ,以便 SurfaceFlinger 可以使用该数据在显示部分合成 Surface 。
FrameBuffer
FrameBuffer 帧缓冲驱动,它是 Linux 的一种驱动程序接口。 Linux 是工作在保护模式下,所以用户态进程是无法象 DOS 那样使用显卡 BIOS 里提供的中断调用来实现直接写屏, Linux 抽象出 FrameBuffer 这个设备来供用户态进程实现直接写屏。 FrameBuffer 机制模仿显卡的功能,将显卡硬件结构抽象掉,可以通过 FrameBuffer 的读写直接对显存进行操作。用户可以将 FrameBuffer 看成是显示内存的一个映像,将其映射到进程地址空间之后,就可以直接进行读写操作,而写操作可以立即反应在屏幕上。这种操作是抽象的统一的。用户不必关心物理显存的位置、换页机制等等具体细节,这些都是由 FrameBuffer 设备驱动来完成的。但 FrameBuffer 本身不具备任何运算数据的能力,就只好比是一个暂时存放水的水池。 CPU 将运算后的结果放到这个水池,水池再将结果流到显示器,中间不会对数据做处理。应用程序也可以直接读写这个水池的内容在这种机制下,尽管 FrameBuffer 需要真正的显卡驱动的支持,但所有显示任务都有 CPU 完成,因此 CPU 负担很重。
在开发者看来, FrameBuffer 本质上是一块显示缓存,往显示缓存中写入特定格式的数据就意味着向屏幕输出内容。所以说 FrameBuffer 就是一块白板。例如对于初始化为 16 位色的 FrameBuffer 来说, FrameBuffer 中的两个字节代表屏幕上一个点,从上到下,从左至右,屏幕位置与内存地址是顺序的线性关系。
帧缓存可以在系统存储器(内存)的任意位置,视频控制器通过访问帧缓存来刷新屏幕。帧缓存也叫刷新缓存 FrameBuffer 或 RefreshBuffer ,这里的帧 Frame 是指整个屏幕范围。帧缓存有个地址,是在内存里。我们通过不停的向 FrameBuffer 中写入数据,显示控制器就自动的从 FrameBuffer 中取数据并显示出来。全部的图形都共享内存中同一个帧缓存。
FrameBuffer 帧缓冲实际上包括两个不同的方面:
Frame:帧,就是指一幅图像,在屏幕上看到的那幅图像就是一帧Buffer:缓冲,就是一段存储区域,可这个区域存储的是帧
FrameBuffer 就是一个存储图形/图像帧数据的缓冲。Linux 内核提供了统一的 Framebuffer 显示驱动,设备节点 /dev/graphics/fb* 或者 /dev/fb* ,以 fb0 表示第一个 Monitor ,当前实现中只用到了一个显示屏。这个虚拟设备将不同硬件厂商实现的真实设备统一在一个框架下,这样应用层就可以通过标准的接口进行图形/图像的输入和输出了:
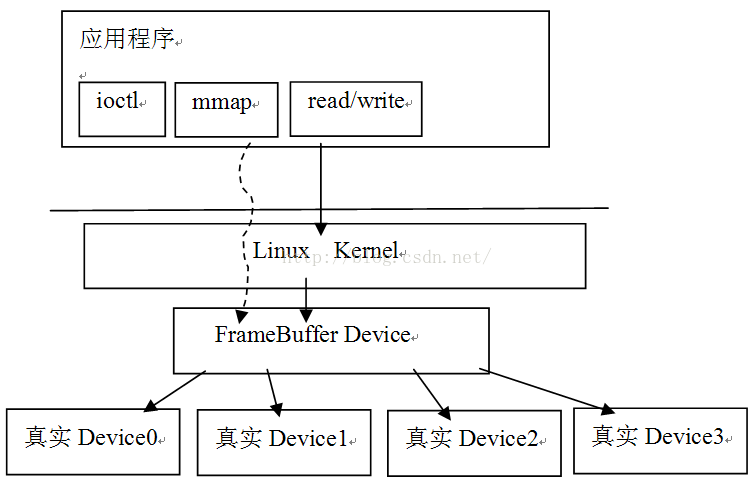
从上图中可以看出,应用层通过标准的 ioctl, mmap 等系统调用,就可以操作显示设备,用起来非常方便。这里 mmap 把设备中的显存映射到用户空间的,在这块缓冲上写数据,就相当于在屏幕上绘画。
Gralloc
Gralloc 的含义为是 Graphics Alloc 图形分配 。 Android 系统在硬件抽象层中提供了一个 Gralloc 模块,封装了对 Framebuffer 的所有访问操作。Gralloc 模块符合 Android 标准的 HAL 架构设计;它分为 fb 和 gralloc 两个设备:前者负责打开内核中的 Framebuffer 、初始化配置,以及提供 post, setSwapInterval 等操作;后者则管理帧缓冲区的分配和释放。上层只能通过 Gralloc 访问帧缓冲区,这样一来就实现了有序的封装保护。
Gralloc 图形内存分配器,分配图像生产者请求的内存。它不仅仅是在原生堆上分配内存的另一种方法;在某些情况下,分配的内存可能并非缓存一致,或者可能完全无法从用户空间访问。分配的性质由用法标记确定,这些标记包括以下属性:
- 从软件
CPU访问内存的频率 - 从硬件
GPU访问内存的频率 - 是否将内存用作
OpenGL ES: GLES纹理 - 视频编码器是否会使用内存
例如如果格式指定为 RGBA 8888 像素,并且指明将从软件访问缓冲区(这意味着应用将直接触摸像素),则分配器必须按照 R-G-B-A 的顺序为每个像素创建 4 个字节的缓冲区。相反如果指明仅从硬件访问缓冲区且缓冲区作为 GLES 纹理,则分配器可以执行 GLES 驱动程序所需的任何操作 - BGRA 排序、非线性搅和布局、替代颜色格式等。允许硬件使用其首选格式可以提高性能。某些值在特定平台上无法组合,例如视频编码器标记可能需要 YUV 像素,因此将无法添加软件访问权并指定 RGBA 8888 。
Gralloc 分配器返回的句柄可以通过 Binder 在进程之间传递。
HWC
HWC: Hardware Composer 硬件混合渲染器,显示子系统的硬件抽象实现。 SurfaceFlinger 可以将某些合成工作委托给 Hardware Composer,以分担 OpenGL 和 GPU 上的工作量。 SurfaceFlinger 只是充当另一个 OpenGL ES 客户端。因此在 SurfaceFlinger 将一个或两个缓冲区合成到第三个缓冲区中的过程中,它会使用 OpenGL ES 。这样使合成的功耗比通过 GPU 执行所有计算更低。Hardware Composer HAL 则进行另一半的工作,并且是所有 Android 图形渲染的核心。 Hardware Composer 必须支持事件,其中之一是 VSYNC(另一个是支持即插即用 HDMI 的热插拔 hotplug ) 。
VSYNC 垂直刷新
先介绍几个概念:
- 帧
视频,动画中的每一张画面,而视频和动画特效就是由无数张画面组合而成,每一张画面都是一帧。 - 帧率
Frame Rate,也指帧速率,单位fps:frames per second,描述视频、电子绘图或游戏每秒播放多少帧;FPS是测量用于保存、显示动态视频的信息数量;我们本篇讲的帧率/帧速率指的是系统显卡处理的速率,即每秒能处理多少帧。
每秒钟帧数愈多,所显示的动作就会愈流畅。通常要避免动作不流畅的最低是 30 ,所以常见的有30fps, 60fps等。wiki百科中提到几个帧率数字:12 fps:由于人类眼睛的特殊生理结构,如果所看画面之帧率高于每秒约 10-12 帧的时候,就会认为是连贯的,是动画的24 fps:有声电影的拍摄及播放帧率均为每秒 24 帧,对一般人而言已算可接受30 fps:早期的高动态电子游戏,帧率少于每秒 30 帧的话就会显得不连贯,这是因为没有动态模糊使流畅度降低60 fps:在实际体验中,60 帧相对于 30 帧有着更好的体验85 fps:一般而言,大脑处理视频的极限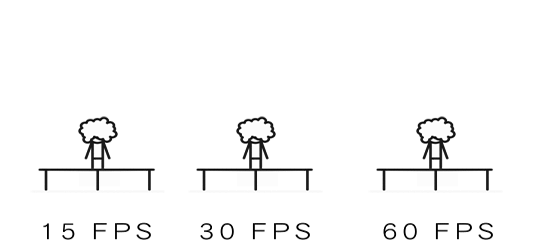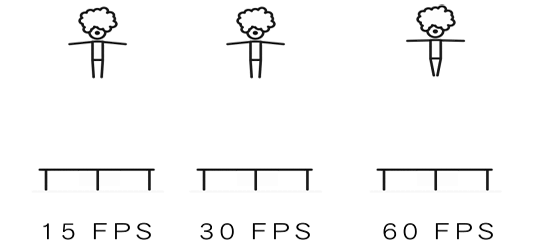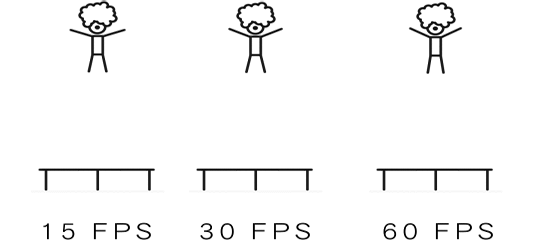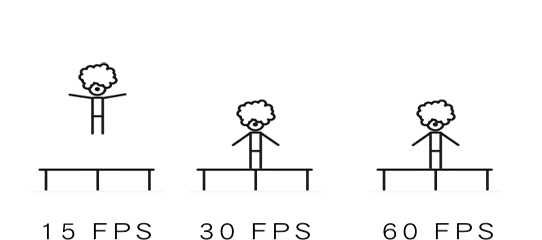
- 屏幕刷新频率
Refresh Rate或者是Scanning Frequency,单位赫兹Hz(即周期/秒),是指设备刷新屏幕的频率,通常为60hz。屏幕的刷新过程是每一行从左到右(行刷新,水平刷新,Horizontal Scanning),从上到下(屏幕刷新,垂直刷新,Vertical Scanning)。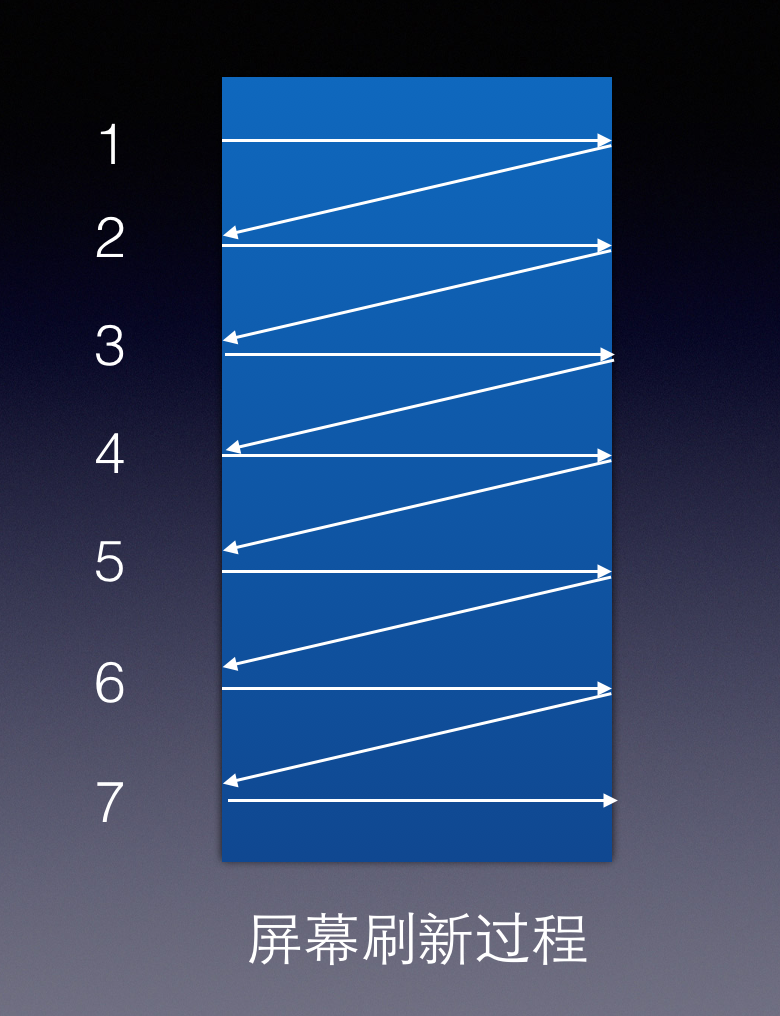
Tearing撕裂
显示出来的图像出现上半部分和下半部分不属于同一帧,我们称之为tearing。假设系统显卡处理能力为FPS 100,显示器的刷新频率是75Hz,显卡将比显示器快1/3;这意味着,在一个刷新周期之内,显卡将写入4/3的帧数据,也就是说下一帧的 1/3 覆盖在前一帧之上;当然随着系统运行, 1/3 这个比例会发生变化,1/3,2/3,1,1/3,循环;这种帧与帧之间的不完全覆盖重合现象就是Tearing撕裂现象。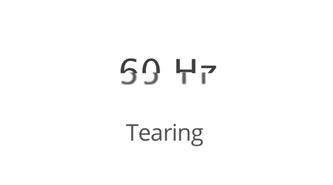
显卡处理图像的帧速率和屏幕刷新频率是相互独立的,当两者不一致时会出现 tearing 问题,为了解决不一致的问题,引入了 Vsync 信号:当整个屏幕刷新完毕,即一个垂直刷新周期完成,会有短暂的空白期,等待定期同步信号 VSync 信号,收到后才开始下一次屏幕刷新;所以 VSync 中的 V 指的是垂直刷新中的垂直 Vertical 。Vsync 技术意味着,显卡显示性能极限被限制在屏幕刷新率以内了:在系统显卡处理的 FPS 高于屏幕刷新率时,显卡会将一部分时间浪费在等待上;因为没有可用的内存用于绘制,显卡需要等待 Vsync 信号才能绘制下一帧。
单缓存缓存模型
理想的情况是帧率和刷新频率相等,每绘制一帧,屏幕显示一帧,如下图所示;但是如果不一致,就会出现tearing。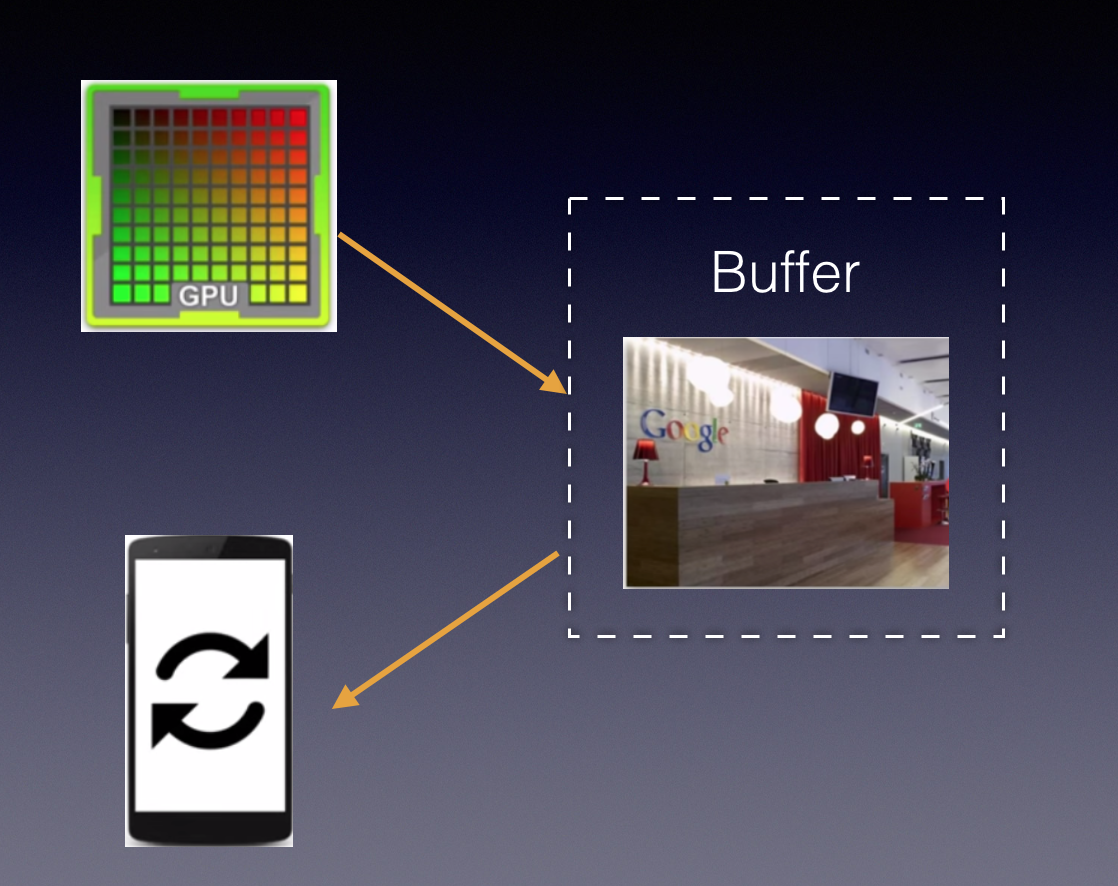
双重缓存
Double Buffer
两个缓存区分别为Back Buffer和Frame Buffer。GPU向Back Buffer中写数据,屏幕从Frame Buffer中读数据。当屏幕刷新完成后产生VSync信号,此时将数据从Back Buffer复制到Frame Buffer,可认为该复制操作在瞬间完成;复制完后显示设备开始显示这帧数据,同时通知CPU/GPU绘制下一帧图像。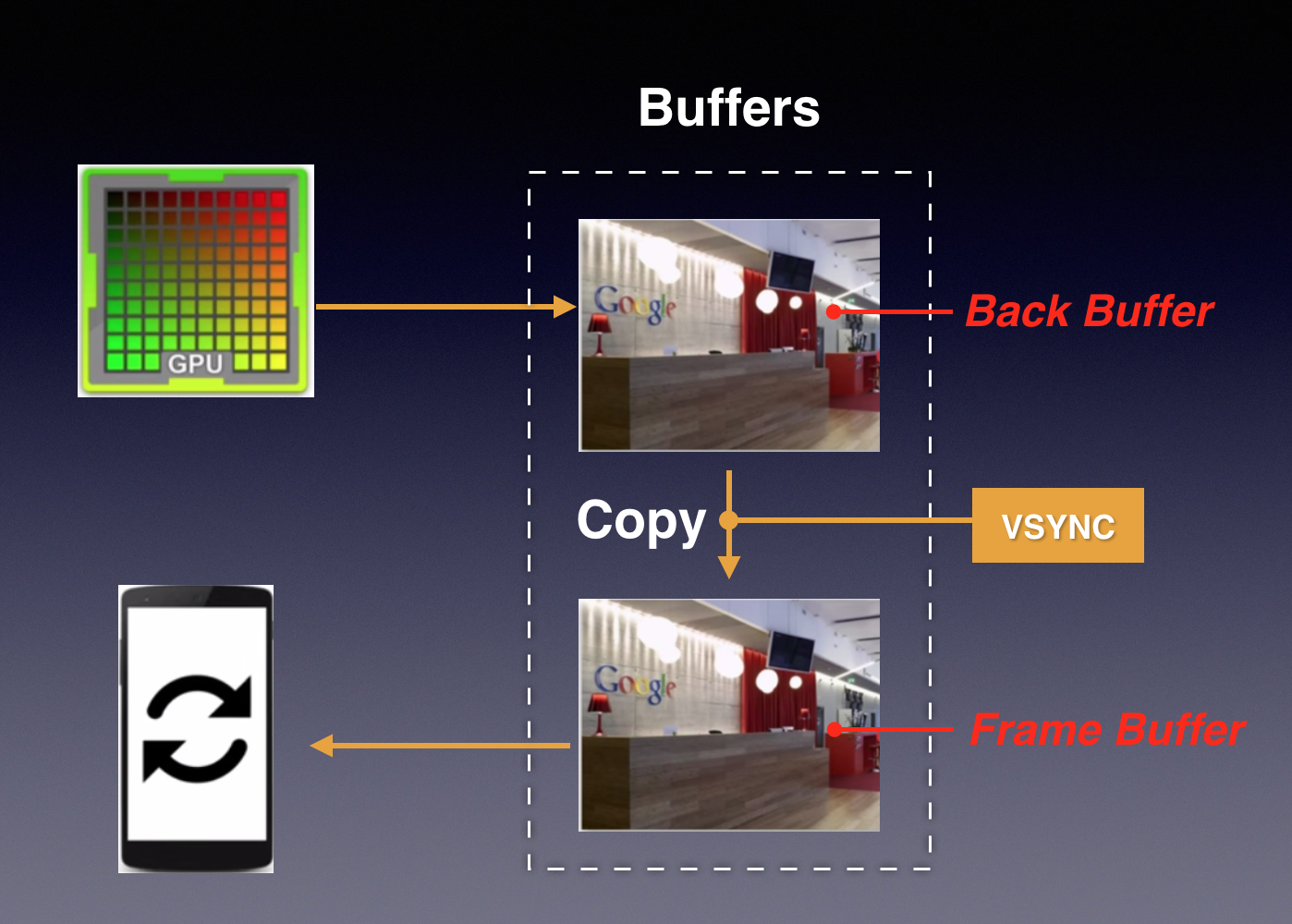
但是当GPU/CPU绘制一帧的时间超过了Vsync时,屏幕刷新从Frame Buffer取到的数据仍然是上一帧数据,即两个Vsync周期显示同一帧数据,我们称为发生了掉帧Dropped Frame, Skipped Frame, Jank现象。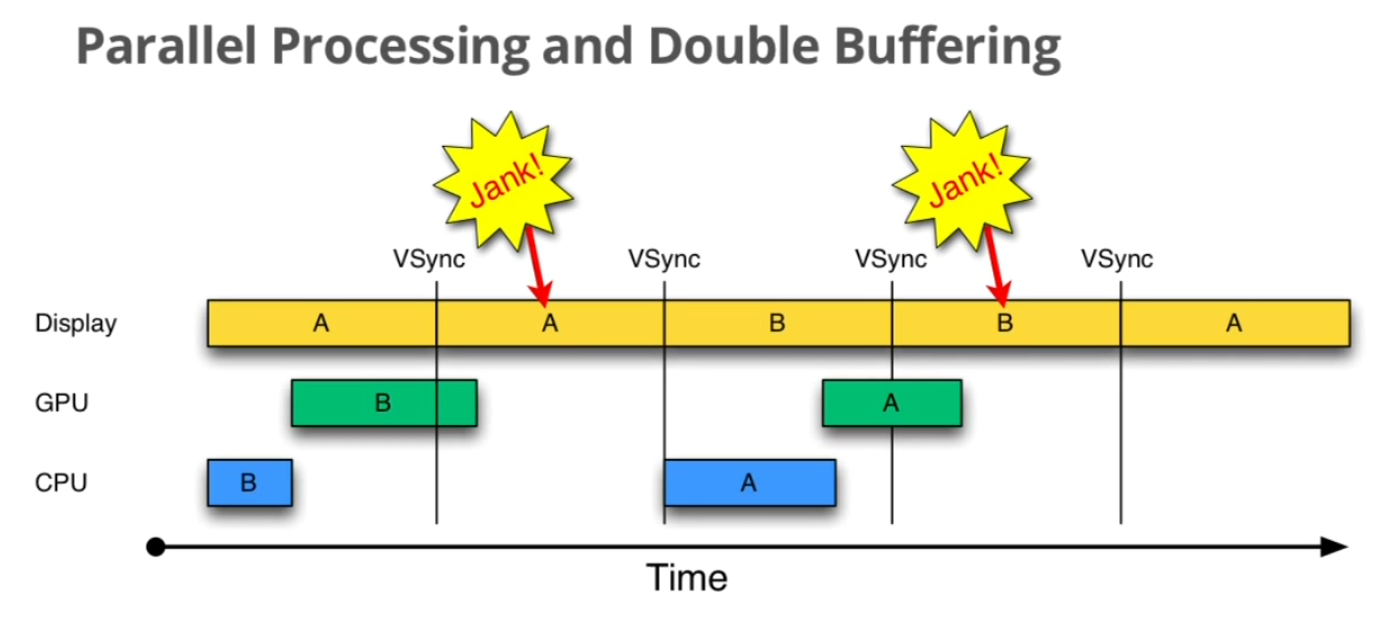
三重缓存
Triple Buffer
在双重缓存模型中,当Jank现象出现时,GPU/CPU此时都处于闲置状态,所以引入了三重缓存的概念:在Jank时,GPU/CPU在第三个Buffer中绘制数据: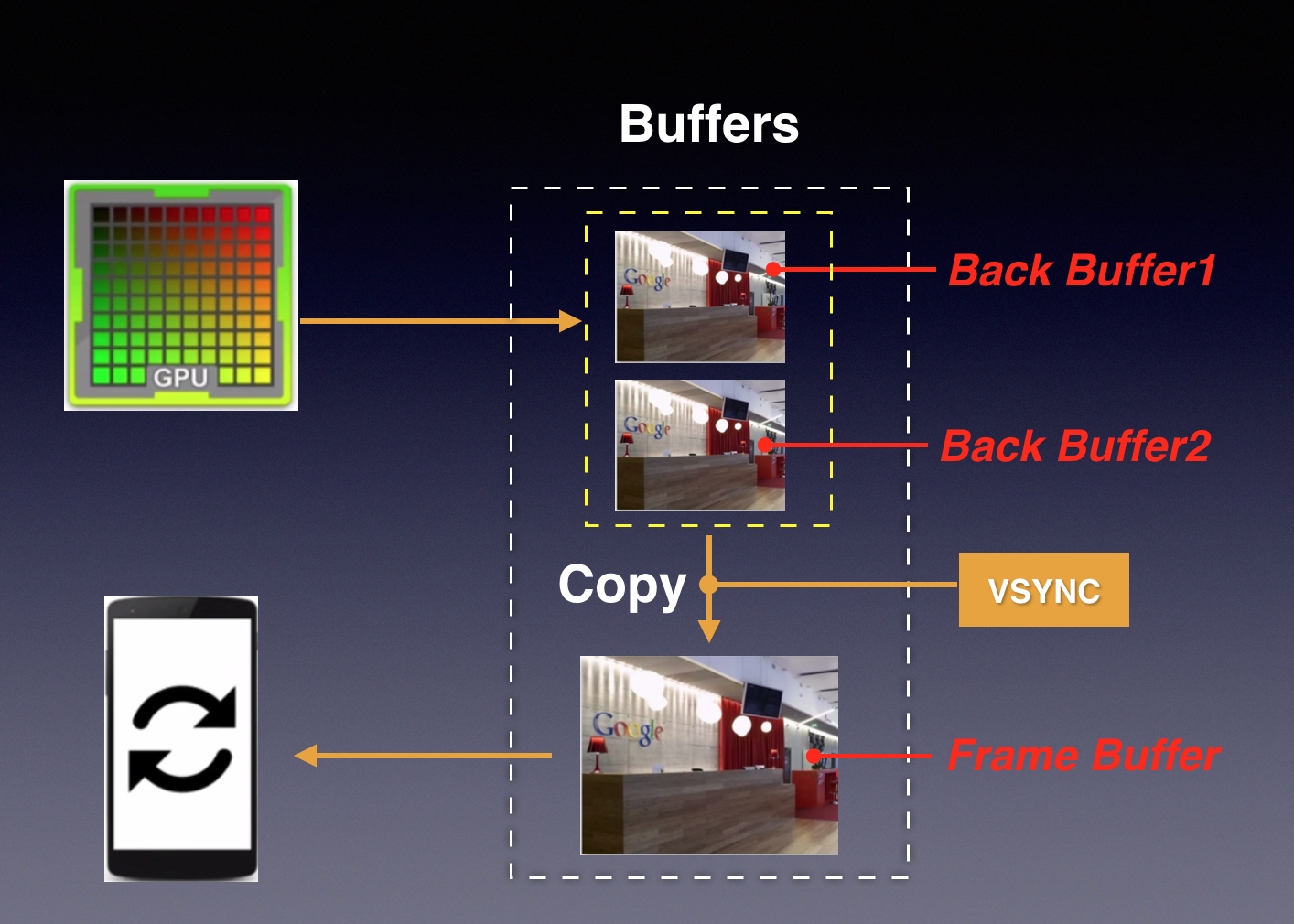
需要注意的是,第三个缓存并不是总是存在的,只要当需要的时候才会创建;而且也无法完全解决Jank现象,但是能缓解。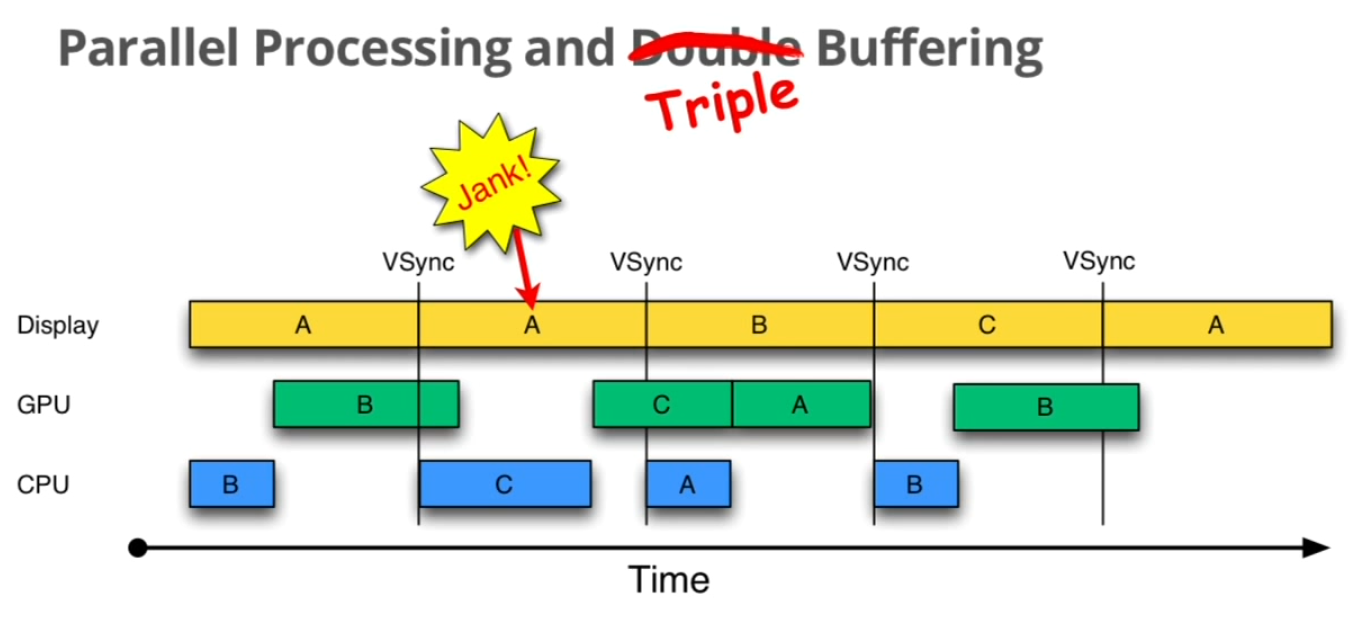
60Hz 和 16 ms
从上面解释帧速率时提到,虽然人眼感知生理的极限 85fps ,但达到 60fps 时动画就已经有很好的体验,不会出现卡顿和迟滞现象;而最为关键的是 60Hz 是美国交流电的频率,如果屏幕刷新频率能够匹配交流电的频率就可以有效的预防屏幕中出现滚动条;所以:
60Hz的屏幕刷新率或者60fps的帧率,是人眼能够感知到比较流畅的数值1000ms/60=16ms,16ms是指GPU/CPU在绘制图形时,必须在这个刷新频率内绘制完成,否则会出现丢帧现象
BufferQueue
实现了整个生产者消费者模型。 BufferQueues 是 Android 图形组件之间的粘合剂。它们是一对队列,可以调解缓冲区从生产者到消费者的固定周期。一旦生产者移交其缓冲区, SurfaceFlinger 便会负责将所有内容合成到显示部分。BufferQueue 永远不会复制缓冲区内容(移动如此多的数据是非常低效的操作);相反缓冲区始终通过句柄进行传递。
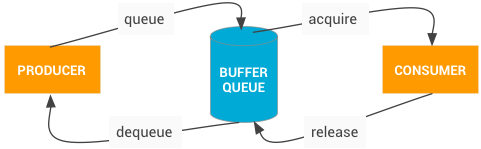
BufferQueue 包含将图像流生产者与图像流消费者结合在一起的逻辑。图像生产者的一些示例包括由相机 HAL 或 OpenGL ES 游戏生成的相机预览。图像消费者的一些示例包括 SurfaceFlinger 或显示 OpenGL ES 流的另一个应用,如显示相机取景器的相机应用。BufferQueue 是将缓冲区池与队列相结合的数据结构,它使用 Binder IPC 在进程之间传递缓冲区。生产者接口,或者您传递给想要生成图形缓冲区的某个人的内容,即是 IGraphicBufferProducer ( SurfaceTexture 的一部分)。 BufferQueue 通常用于渲染到 Surface ,并且与 GL 消费者及其他任务一起消耗内容。 BufferQueue 可以在三种不同的模式下运行:
- 类同步模式
默认情况下,BufferQueue在类同步模式下运行,在该模式下,从生产者进入的每个缓冲区都在消费者那退出。在此模式下不会舍弃任何缓冲区。如果生产者速度太快,创建缓冲区的速度比消耗缓冲区的速度更快,它将阻塞并等待可用的缓冲区。 - 非阻塞模式
BufferQueue还可以在非阻塞模式下运行,在此类情况下,它会生成错误,而不是等待缓冲区。在此模式下也不会舍弃缓冲区。这有助于避免可能不了解图形框架的复杂依赖项的应用软件出现潜在死锁现象。 - 舍弃模式
BufferQueue可以配置为丢弃旧缓冲区,而不是生成错误或进行等待。例如,如果对纹理视图执行GL渲染并尽快绘制,则必须丢弃缓冲区。
为了执行这项工作的大部分环节, SurfaceFlinger 就像另一个 OpenGL ES 客户端一样工作。例如当 SurfaceFlinger 正在积极地将一个缓冲区或两个缓冲区合成到第三个缓冲区中时,它使用的是 OpenGL ES 。
数据流
Android 图形管道数据流如下图所示:
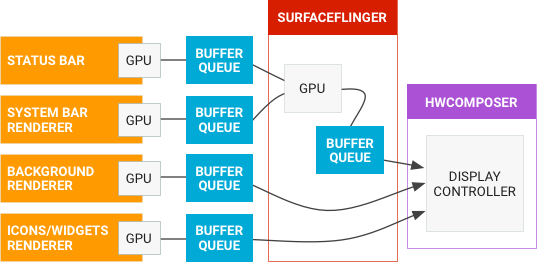
左侧的对象是生成图形缓冲区的渲染器,如主屏幕、状态栏和系统界面。 SurfaceFlinger 是合成器,而硬件混合渲染器是制作器。
组件小结
- 低级别组件
BufferQueue和gralloc。BufferQueue将可生成图形数据缓冲区的组件(生产者)连接到接受数据以便进行显示或进一步处理的组件(消费者)。通过供应商专用HAL接口实现的gralloc内存分配器将用于执行缓冲区分配任务。SurfaceFlinger, Hardware Composer和虚拟显示屏。SurfaceFlinger接受来自多个源的数据缓冲区,然后将它们进行合成并发送到显示屏。Hardware Composer HAL (HWC)确定使用可用硬件合成缓冲区的最有效的方法,虚拟显示屏使合成输出可在系统内使用(录制屏幕或通过网络发送屏幕)。Surface, Canvas, SurfaceHolder。Surface可生成一个通常由SurfaceFlinger使用的缓冲区队列。当渲染到Surface上时,结果最终将出现在传送给消费者的缓冲区中。Canvas API提供一种软件实现方法(支持硬件加速),用于直接在Surface上绘图(OpenGL ES的低级别替代方案)。与视图有关的任何内容均涉及到SurfaceHolder,其API可用于获取和设置Surface参数(如大小和格式)。EGLSurface, OpenGL ES。OpenGL ES (GLES)定义了用于与EGL结合使用的图形渲染API。EGI是一个规定如何通过操作系统创建和访问窗口的库(要绘制纹理多边形,请使用GLES调用;要将渲染放到屏幕上,请使用EGL调用)。ANativeWindow,它是Java Surface类的C/C++等价类,用于通过原生代码创建EGL窗口Surface。Vulkan。Vulkan是一种用于高性能3D图形的低开销、跨平台API。与OpenGL ES一样,Vulkan提供用于在应用中创建高质量实时图形的工具。Vulkan的优势包括降低CPU开销以及支持SPIR-V二进制中间语言。
- 高级别组件
SurfaceView和GLSurfaceView。SurfaceView结合了Surface和View。SurfaceView的View组件由SurfaceFlinger(而不是应用)合成,从而可以通过单独的线程/进程渲染,并与应用界面渲染隔离。GLSurfaceView提供帮助程序类来管理EGL上下文、线程间通信以及与Activity生命周期的交互(但使用GLES时并不需要GLSurfaceView)。SurfaceTexture。SurfaceTexture将Surface和GLES纹理相结合来创建BufferQueue,而应用是BufferQueue的消费者。当生产者将新的缓冲区排入队列时,它会通知应用。应用会依次释放先前占有的缓冲区,从队列中获取新缓冲区并执行EGL调用,从而使GLES可将此缓冲区作为外部纹理使用。Android 7.0增加了对安全纹理视频播放的支持,以便用户能够对受保护的视频内容进行GPU后处理。TextureView。TextureView结合了View和SurfaceTexture。TextureView对SurfaceTexture进行包装,并负责响应回调以及获取新的缓冲区。在绘图时,TextureView使用最近收到的缓冲区的内容作为其数据源,根据View状态指示,在它应该渲染的任何位置和以它应该采用的任何渲染方式进行渲染。View合成始终通过GLES来执行,这意味着内容更新可能会导致其他View元素重绘。
高级别组件可以直接在 APP 中使用。
Buffer/Window 体系
代码速查表
1 | system/core/libcutils/include/cutils/native_handle.h |
native_handle/buffer_handle_t
先看 native_handle 这个结构体的定义:
1 | // native_handle.h |
native_handle 这个结构体,描述了一个数据结构,其中最关键的是 data[0] ,它是一个长度为 0 的数组,即 native_handle 是一个柔性数组。在标准的 C/C++ 中,长度为 0 的数组是不被允许的,编译时会产生错误!长度为 0 的数组是 C/C++ 的扩展,需要当前编译器支持这个扩展。从头文件注释中也可以看出,当使用的是 clang 编译器时,才会定义 data[0] 并且忽略数组为 0 的警告。
从 C/C++ 中柔性数组的用途来看, native_handle 表示的是一个不定长数据结构,实际意义指向连续分配的内存空间(除了 native_handle 之外)代表的数据结构(通常是 private_handle_t )。这里这么做,是因为显示系统和每家实现平台相关度很高, native_handle 定义一个通用的数据结构,至于显示系统如何显示,每家自己去实现对应的 private_handle_t 。
native_handle 结构体中的注释写的很清楚, numFds 表示被指向数据结构包含几个文件描述符; numInts 表示被指向数据结构长度是多少个整型;有了这两个信息后,内存分配就很容易了,参考 native_handle_create 的源码实现:
1 | // native_handle.c |
小结: native_handle, native_handle_t 表示一个不定长数据结构,而 buffer_handle_t 表示指向 native_handle 的指针。
private_handle_t
private_handle_t 描述的是一块缓存,因为和实现平台高度相关,我这里选取高通平台,先看头文件定义:
1 | // gralloc_priv.h |
private_handle_t 描述了缓存区使用的文件描述符 fd, fd_metadata 、大小、偏移量、基地址、长宽、格式、没有对齐的长宽等等,而 sNumFds 对应 nativeHandle.numFds ; sNumInts 对应 nativeHandle.numInts ,即除了文件描述符之外,该数据结构的长度。
小结: private_handle_t 在各个模块之间传递的时候很不方便,而如果用 native_handle 的来传递,就可以消除平台的差异性。一个简单示意图描述两者的关系:

至此,我们可以简单的理解为 native_handle, native_handle_t, private_handle_t, buffer_handle_t 表示的是同一块内存。
ANativeWindowBuffer
先了解 android_native_base_t 数据结构的定义:
1 | typedef struct android_native_base_t |
android_native_base_t 中 incRef/decRef 主要功能是:为了把派生类和 Android 所有 class 的老祖宗 RefBase 联系起来所预留的函数指针。
再看 ANativeWindowBuffer 数据结构的定义:
1 | // nativebase.h |
ANativeWindowBuffer 中使用了 native_handle_t 指针,同时该结构体中也有长宽、格式、步进等基本描述信息;也就是 ANativeWindowBuffer 描述的是一块 Window 相关的缓存区。
ANativeWindow
ANativeWindow 数据结构的定义:
1 | // window.h |
从数据结构定义中可以看出, ANativeWindow 和窗口属性相关,它表示的是一个底层实现的窗口,定义的各种函数指针都是对 ANativeWindowBuffer 内存的操作;而 fenceFd 可以看成这个 buffer 的锁。
小结:不管是 ANativeWindow, ANativeWindowBuffer 它们都包含 android_native_base_t 结构体,但是都没有对 incRef, decRef 赋值;可以认为 ANativeWindow, ANativeWindowBuffer 为抽象数据结构。
ANativeObjectBase 模板
ANativeObjectBase 是一个模板类,定义如下:
1 | // ANativeObjectBase.h |
ANativeObjectBase 模板类的主要作用就是实现 incRef, decRef 引用计数,以及父类子类的类型转换。
GraphicBuffer
先看 GraphicBuffer 的头文件定义:
1 | // GraphicBuffer.h |
GraphicBuffer 使用 ANativeObjectBase 模板,即 GraphicBuffer 就是 ANativeWindowBuffer 的一种具体实现;而 ANativeWindowBuffer.common 成员的两个函数指针 incRef, decRef 指向了 GraphicBuffer 的另一个基类 RefBase 的 incStrong, decStrong ;而 ANativeWindowBuffer 可以看做是把 buffer_handle_t 包了一层,所以 GraphicBuffer 也是指向的一块缓存区。
Surface
Surface 的头文件定义:
1 | // Surface.h |
Surface 也使用了 ANativeObjectBase 模板,即 Surface 就是 ANativeWindow 的一种具体实现,同样也继承了 RefBase 实现引用计数。另外成员数据结构 BufferSlot 是对 GraphicBuffer 的包装,而 mSlots 数组表示每个 Surface 中包含 NUM_BUFFER_SLOTS 个 GraphicBuffer 缓存。
而 Surface 的构造函数中,也将 ANativeWindow 的函数指针进行了赋值:
1 | // Surface.cpp |
小结
native_handle/native_handle_t是private_handle_t的抽象表示方法,消除平台相关性;方便private_handle_t所表示的缓存区可以在Android各个层次之间传递;而buffer_handle_t是指向他们的指针ANativeWindowBuffer将buffer_handle_t进行了包装;ANativeWindow, ANativeWindowBuffer都继承于android_native_base_t,它定义了引用计数两个函数指针;可以认为ANativeWindow, ANativeWindowBuffer为抽象数据结构,表示窗口和其对应缓存GraphicBuffer, Surface都使用了模版类ANativeObjectBase,都继承了RefBase实现incRef, decRef引用计数;它们是具体的实现类,即实现具体的窗口缓存和窗口Surface的成员BufferSlot mSlots[NUM_BUFFER_SLOTS];可以看作是sp<GraphicBuffer>类型的数组;也就是说每个Surface中都包含有NUM_BUFFER_SLOTS个GraphicBufferSurface, GraphicBuffer是图形显示系统的高层类,后续主要围绕这两个类来介绍;一个代表窗口,一个代表窗口对应的缓存

BufferQueue 中的 Buffer 对象,我们用的都是 GraphicBuffer 。 Surface 是 Andorid 窗口的描述,是 ANativeWindow 的实现;同样 GraphicBuffer 是 Android 中图形 Buffer 的描述,是 ANativeWindowBuffer 的实现。而一个窗口可以有多个 Buffer 。
libui 库
libui.so 库主要是 GraphicBuffer 缓存相关的代码,包含缓存分配,映射当当前进程等等,而 IAllocator, IMapper 具体是在 HAL 中实现的。
代码目录结构
frameworks/native/libs/ui 目录结构:
1 | ui |
GraphicBufferAllocator/GraphicBufferMapper
它们两个都是包装类,包装了 IAllocator, IMapper ,而这两个类都是在 HAL Gralloc2 中实现的。
GraphicBufferAllocator
缓存分配,包装了IAllocator类。GraphicBufferMapper
缓存映射到当前进程,包装了IMapper类。
GraphicBuffer
GraphicBuffer 继承 ANativeWindowBuffer ,并持有 GraphicBufferMapper 映射对应的缓存区。
1 | class GraphicBuffer : |
Fence 机制
Fence 是一种同步机制,主要用于 GraphicBuffer 的同步。它主要被用来处理跨硬件的情况,尤其是 CPU, GPU, HWC 之间的同步,另外它还可以用于多个时间点之间的同步。 GPU 编程和纯 CPU 编程一个很大的不同是它是异步的,也就是说当我们调用 GL command 返回时这条命令并不一定完成了,只是把这个命令放在本地的 command buffer 里,而 Fence 机制就是解决这些同步问题的。Fence 顾名思义就是把先到的拦住,等后来的,两者步调一致了再往前走。抽象地说,Fence 包含了同一或不同时间轴上的多个时间点,只有当这些点同时到达时 Fence 才会被触发。 Fence 可以由硬件实现 Graphic driver,也可以由软件实现 Android kernel 中的 sw_sync 。
Fence 的主要实现代码路径:
1 | frameworks/native/libs/ui/Fence.cpp |
总得来说, kernel driver 部分是同步的主要实现,libsync 是对 driver 接口的封装, Fence 是对 libsync 的进一步的 C++ 封装。 Fence 会被作为 GraphicBuffer 的附属随着 GraphicBuffer 在生产者和消费间传输; SyncFeatures 用以查询系统支持的同步机制。
DisplayInfo 显示信息
1 | // DisplayInfo.h |
DisplayInfo 结构体包含了显示屏幕的基本信息:
- 屏幕分辨率
Resolution
屏幕的宽高是用分辨率Resolution来描述的,也就是有多少个像素点。屏幕宽度,即屏幕横向可以显示多少个像素点;屏幕高度,即屏幕纵向可以显示多少给像素点。平常所说的720P: 1080x720屏幕,即横向可以显示 1080 个像素点,纵向可以显示 720 个像素点。如下为常见屏幕分辨率: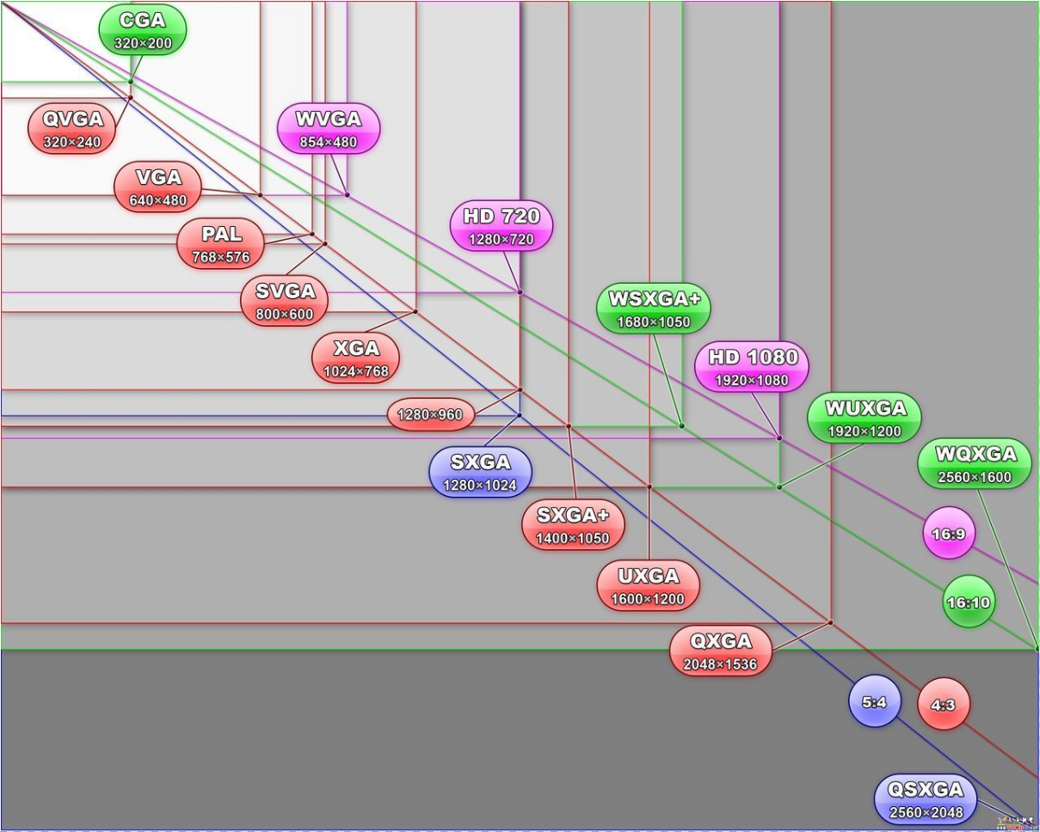
- 屏幕
DPIDPI: Dots Per Inch每英寸点数,是一个度量单位,表示屏幕每英寸上有多少个物理点。常见屏幕物理大小,是用英寸来描述屏幕对角线的长度,比如IPhone X的大小 5.8 寸,即屏幕对角线长度为 5.8 英寸。*标准DPI为160dpi*,人类视网膜级通常为300dpi。PPI: Pixel Per Inch每英寸像素,也是度量单位,表示每英寸显示多少个像素。通常情况下DPI, PPI设为相同,表示每个物理点显示一个像素;但是好一点的显示器,可能DPI比PPI大,即一个像素由多个物理点来显示。 - 密度
DensityDIP: Density Independent Pixels设备无关像素,通常简写为DP=DIP,请注意DPI做好区分。DP表示这个像素的数值是和设备无关的,那实际转换时怎么转换呢?Density密度,实际是一个缩放因子,它表示当前设备实际DPI和标准DPI的比例值;比如设备实际DPI为320dpi,那么density=320/160=2,即density为 2 。有了density之后,dp, px可以使用公式来转换px=density*dp。
所以我们在APP布局设计中,所有显示设置的距离,通常使用dp来计算,来规避不同屏幕特性。 - 屏幕刷新率
FPS
这里屏幕刷新率使用FPS来表示,不是Hz,表示屏幕每秒能显示多少帧数据;通常为 60 fps ,即 16 ms 刷新一次。 - 屏幕旋转方向
orientations
手机默认竖屏,0 表示竖屏, 180 表示横屏。 - 屏幕安全性
secure
这主要是用于DRM数字版权保护时,确保显示的设备是安全的,以防止DRM的内容被在显示的过程中被截取,只有安全的设备才能显示DRM的内容。Android默认所有的非虚拟显示都是安全的。 appVsyncOffset, presentationDeadline
这两个都和Vsync有关;appVsyncOffset是一个偏移量,在系统或硬件Vsync的基础上做一些偏移;presentationDeadline表示,一帧数据必现在这个时间内显示出来。
libgui 库
代码目录结构
frameworks/native/libs/gui 目录结构:
1 | gui/ |
其中 H2B, B2H 表示 Framework Buffer 和 HAL 层数据结构的相互转换;实际上代表的是同一样东西,方便各层内部使用。
IGraphicBufferProducer/IProducerListener 生产者
IGraphicBufferProducer 是生产者接口,实现了 IInterface 可以用于跨进程通信。
1 | // IGraphicBufferProducer.h |
IProducerListener 是 IGraphicBufferProducer 对应的回调接口。
1 | // IProducerListener.h |
IGraphicBufferConsumer/IConsumerListener 消费者
IGraphicBufferConsumer 是消费者接口,实现了 IInterface 可以用于跨进程通信。
1 | // IGraphicBufferConsumer.h |
IConsumerListener 是 IGraphicBufferConsumer 对应的回调接口:
1 | // IConsumerListener.h |
BufferItem
BufferItem 描述了一块缓存 GraphicBuffer ,以及位置 mSlot ,同步 mFence 等等信息。
1 | // BufferItem.h |
BufferSlot
BufferSlot 记录了当前 slot 位置的缓存 GraphicBuffer ,以及对应状态, EGL 相关信息。
1 | // BufferSlot.h |
BufferQueueDefs 中定义了一个 BufferSlot 的数组结构类型 SlotsType 。
1 | // BufferQueueDefs.h |
BufferQueueCore
BufferQueueCore 是生产者消费模型的核心,如下是几个重要的成员变量:
1 | // BufferQueueCore.h |
mQueue
是一个新建先出队列,存储了一队BufferItem数据,即一组缓存区。mSlots
一个数组,保存了BufferSlot数据,每个slot位置对应一个缓存。mConsumerListener
当前生产消费模型中的,消费者回调接口。mConnectedProducerListener
当前生产消费模型中的,生产者回调接口。
BufferQueueProducer/BufferQueueConsumer 生产者/消费者实现类
BufferQueueProducer 是 IGraphicBufferConsumer 的实现类,实现了生产者对应的功能。
1 | // BufferQueueProducer.h |
BufferQueueProducer 中持有 BufferQueueCore 对象; mSlots 指向 mCore->mSlots ;同时保持了生产消费模型中,对应消费者的名称。
BufferQueueConsumer 是 IGraphicBufferConsumer 的实现类,实现了消费者对应的功能。
1 | // BufferQueueConsumer.h |
BufferQueueConsumer 中持有 BufferQueueCore 对象; mSlots 指向 mCore->mSlots 。
BufferQueue 模型
BufferQueue 类是 Android 中所有图形处理操作的核心。它的作用很简单:将生成图形数据缓冲区的一方(生产者)连接到接受数据以进行显示或进一步处理的一方(消费者)。几乎所有在系统中移动图形数据缓冲区的内容都依赖于 BufferQueue 。
基本用法很简单:生产者请求一个可用的缓冲区 dequeueBuffer ,并指定一组特性,包括宽度、高度、像素格式和用法标记;生产者填充缓冲区并将其返回到队列 queueBuffer 。随后消费者获取该缓冲区 acquireBuffer ,并使用该缓冲区的内容。当消费者操作完毕后,将该缓冲区返回到队列 releaseBuffer 。
最新的 Android 设备支持“同步框架”,这使得系统能够在与可以异步处理图形数据的硬件组件结合使用时提高工作效率。例如,生产者可以提交一系列 OpenGL ES 绘制命令,然后在渲染完成之前将输出缓冲区加入队列。该缓冲区伴有一个栅栏,当内容准备就绪时,栅栏会发出信号。当该缓冲区返回到空闲列表时,会伴有第二个栅栏,因此消费者可以在内容仍在使用期间释放该缓冲区。该方法缩短了缓冲区通过系统时的延迟时间,并提高了吞吐量。
队列的一些特性(例如可以容纳的最大缓冲区数)由生产者和消费者联合决定。但是 BufferQueue 负责根据需要分配缓冲区。除非特性发生变化,否则将会保留缓冲区;例如,如果生产者请求具有不同大小的缓冲区,则系统会释放旧的缓冲区,并根据需要分配新的缓冲区。
生产者和消费者可以存在于不同的进程中; BufferQueue 永远不会复制缓冲区内容(移动如此多的数据是非常低效的操作),缓冲区始终通过句柄进行传递。
1 | // BufferQueue.h |
BufferQueue 的头文件定义很简单:
- 定义了一个
ConsumerListener的弱引用 - 整个类只有一个函数
createBufferQueue,它将参数中的IGraphicBufferProducer, IGraphicBufferConsumer消费者关联起来 - 没有构造函数,只能通过
createBufferQueue来创建对象 BufferQueue中并不包含队列数据结构来存储缓存,仅仅连接了生产者、消费者两者的关系
来看 createBufferQueue 的具体实现:
1 | // BufferQueue.cp |
上面代码删掉了 LOG 打印及空判断,整个代码流程非常简单:
- 新建
BufferQueueCore core - 由
core新建生产者IGraphicBufferProducer - 由
core新建消费者IGraphicBufferConsumer
也就是说 BufferQueueCore 是最终的纽带,保存了生产者消费者对应的缓存区,连接了两者的关系。
Surface
Surface 代表着窗口,它包含一个生产者 IGraphicBufferProducer 用来填充缓存,也就是窗口中用来显示在屏幕上的内容,mSlot 数组表示可以有多个缓存区。
1 | // Surface.h |
ISurfaceComposer/ISurfaceComposerClient
ISurfaceComposerClient/ISurfaceComposer 都继承了 IInterface ,它们俩分别代表 Surface 合成的客户端和服务端,具体在 SurfaceFlinger 服务进程中实现, libgui 中只对合成能力(函数)做了定义。
1 | // ISurfaceComposerClient.h |
如下是 ISurfaceComposerClient 相关的类图结构:
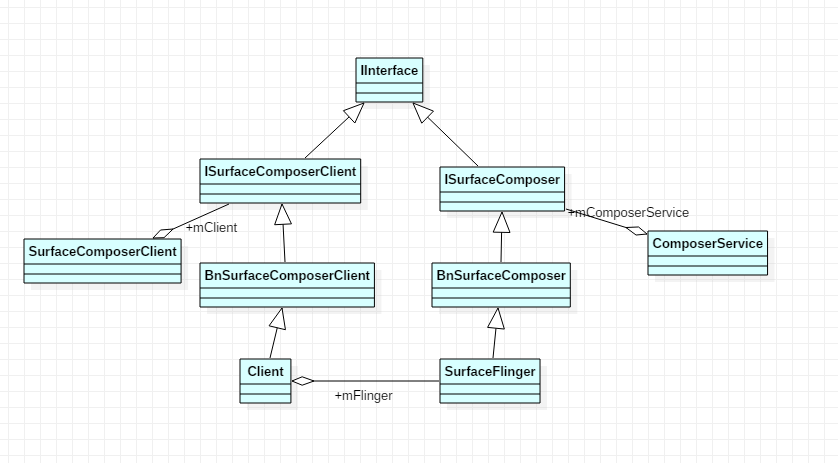
先看 ComposerService ,它代表着 SurfaceFlinger 服务端,头文件定义如下:
1 | // ComposerService.h |
查看 connectLocked, getComposerService 两个函数的实现:
1 | // SurfaceComposerClient.cpp |
connectLocked 连接过程就是等待 SurfaceFlinger 服务启动后并获取它; getComposerService 直接返回已经连接成功的实例 mComposerService 。
再看 SurfaceComposerClient ,可以将它理解为应用端,是 SurfaceFlinger 服务的客户端,它将建立和 SurfaceFlinger 服务的通信,头文件定义如下:
1 | // SurfaceComposerClient.h |
mClient 实际对应的是 SurfaceFlinger 进程中的 Client.cpp ,查看 SurfaceComposerClient::onFirstRef 源码:
1 | // SurfaceComposerClient.cpp |
SurfaceComposerClient 中有一个重要功能就是创建 Surface ,对应源码:
1 | // SurfaceComposerClient.cpp |
最终会调用 SurfaceFlinger 中的 mClient 来创建 Layer, IGraphicBufferProducer ;而具体的 Surface 则由 SurfaceControl 来创建。
SurfaceControl
SurfaceControl 持有创建的 Surface 的强引用,头文件定义:
1 | // SurfaceControl.h |
mHandle 指向 SurfaceFlinger 创建的 Layer 。而 SurfaceControl::createSurface 直接 new 了一个 Surface 对象。
1 | // SurfaceControl.cpp |
IDisplayEventConnection 显示连接
IDisplayEventConnection 继承了 IInterface ,客户端 APP 通过它向服务端 SurfaceFlinger 发送刷新请求。
1 | class IDisplayEventConnection : public IInterface { |
IDisplayEventConnection 的类图结构
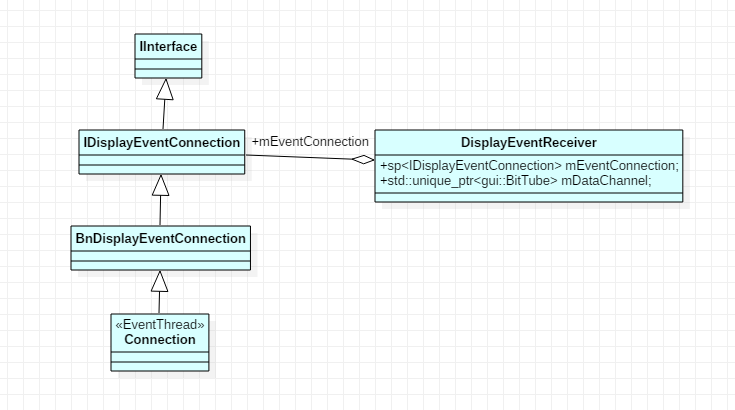
IDisplayEventConnection 的具体实现是在 SurfaceFlinger 进程中的 EventThread::Connection ;DisplayEventReceiver 持有该实例。
小结
libgui中一共提供了 4 组IInterface接口:IGraphicBufferProducer/IProducerListener, IGraphicBufferConsumer/IConsumerListener, ISurfaceComposerClient/ISurfaceComposer, IDisplayEventConnectionIGraphicBufferProducer/IProducerListener生产者模型IGraphicBufferConsumer/IConsumerListener消费者模型ISurfaceComposerClient/ISurfaceComposer提供创建Surface的功能,及相关管理IDisplayEventConnection提供了APP客户端请求服务端SurfaceFlinger刷新的接口
SurfaceFlinger
代码速查表
1 | surfaceflinger/ |
surfaceflinger 进程
SurfaceFlinger 是以独立进程运行的,进程名为 surfaceflinger ,对应的 rc 文件如下:
1 | // surfaceflinger.rc |
surfaceflinger 服务属于核心类 core,当 surfaceflinger 重启时会触发 zygote 的重启。接下来看进程 main 方法对应文件为:
1 | // main_surfaceflinger.cpp |
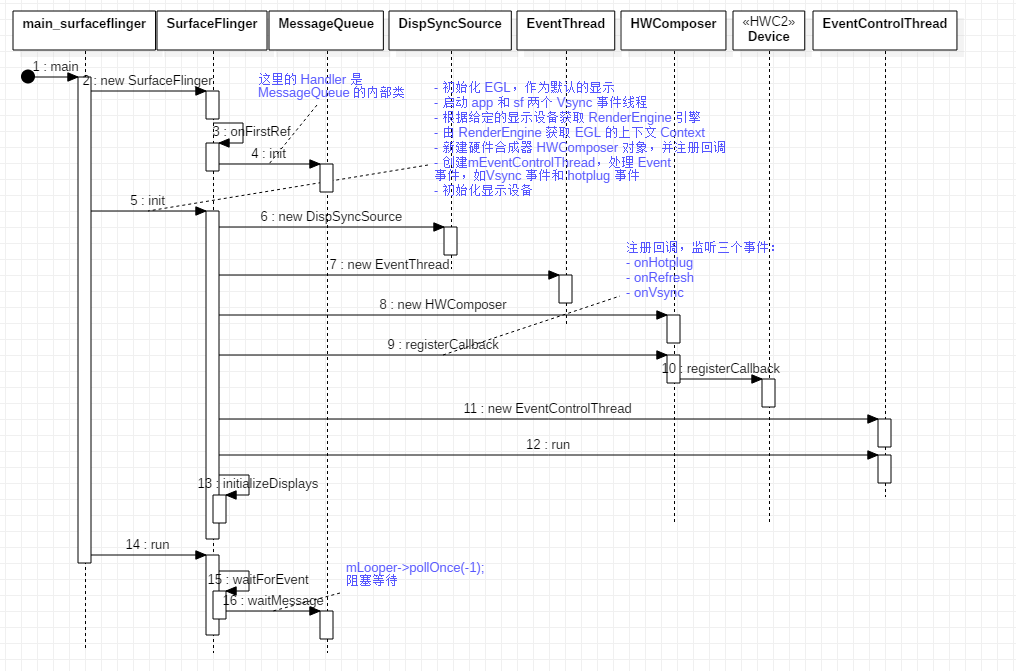
surfaceflinger 进程的 main 函数中主要做了 4 件事:
- 通过
DisplayUtils创建SurfaceFlinger对象 SurfaceFlinger对象调用init方法,实现初始化SurfaceFlinger向系统注册Binder服务SurfaceFlinger对象调用run方法,该方法是一个do-while无限循环
初始化流程
DisplayDevice 显示设备
1 | // DisplayDevice.h |
显示设备有三种类型:主显、外显、虚显;每添加一个显示屏,都会创建一个 DisplayDevice 。
Layer 层
Layer 是 SurfaceFlinger 进行合成的基本操作单元。Layer 在应用请求创建 Surface 的时候在 SurfaceFlinger 内部创建,因此一个 Surface 对应一个 Layer 。每个 Layer 包含常见属性:
Z orderAlpha value from 0 to 255visibleRegioncrop regiontransformation: rotate 0, 90, 180, 270: flip H, V: scale
当多个 Layer 进行合成的时候,并不是整个 Layer 的空间都会被完全显示,根据这个 Layer 最终的显示效果,一个 Layer 可以被划分成很多的 Region , 在 SurfaceFlinger 中定义了以下几种类型:
TransparantRegion:完全透明的区域,在它之下的区域将被显示出来OpaqueRegion:完全不透明的区域,是否显示取决于它上面是否有遮挡或是否透明VisibleRegion:可见区域,包括完全不透明无遮挡区域或半透明区域;即visibleRegion = Region - above OpaqueRegion.CoveredRegion:被遮挡区域,在它之上,有不透明或半透明区域DirtyRegion:可见部分改变区域,包括新的被遮挡区域,和新的露出区域
头文件定义:
1 | // Layer.h |
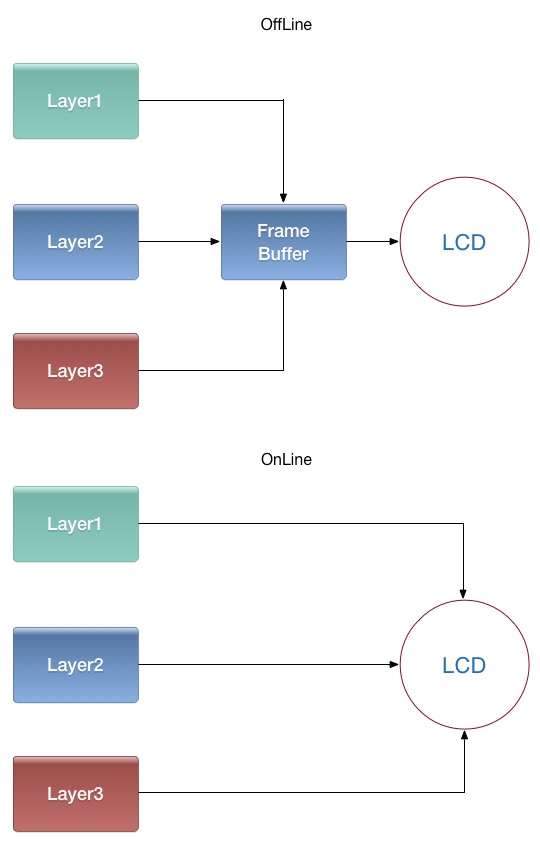
SurfaceFlinger 接收所有 Surface 作为输入,根据 Z-Order, 透明度,大小,位置等参数,计算出每个 Surface 在最终合成图像中的位置,然后交由 HWComposer, OpenGL 生成最终的显示 Buffer , 然后显示到特定的显示设备上。Layer 的合成分为两种,离线合成和在线合成:
- 离线合成
先将所有图层画到一个最终层FrameBuffer上,再将FrameBuffer送到LCD显示。由于合成FrameBuffer与送LCD显示一般是异步的(线下生成FrameBuffer,需要时线上的LCD去取),因此叫离线合成。 - 在线合成
不使用FrameBuffer,在LCD需要显示某一行的像素时,用显示控制器将所有图层与该行相关的数据取出,合成一行像素送过去。只有一个图层时,又叫Overlay技术。
由于省去合成FrameBuffer时读图层,写FrameBuffer的步骤,大幅降低了内存传输量,减少了功耗,但这个需要硬件支持。
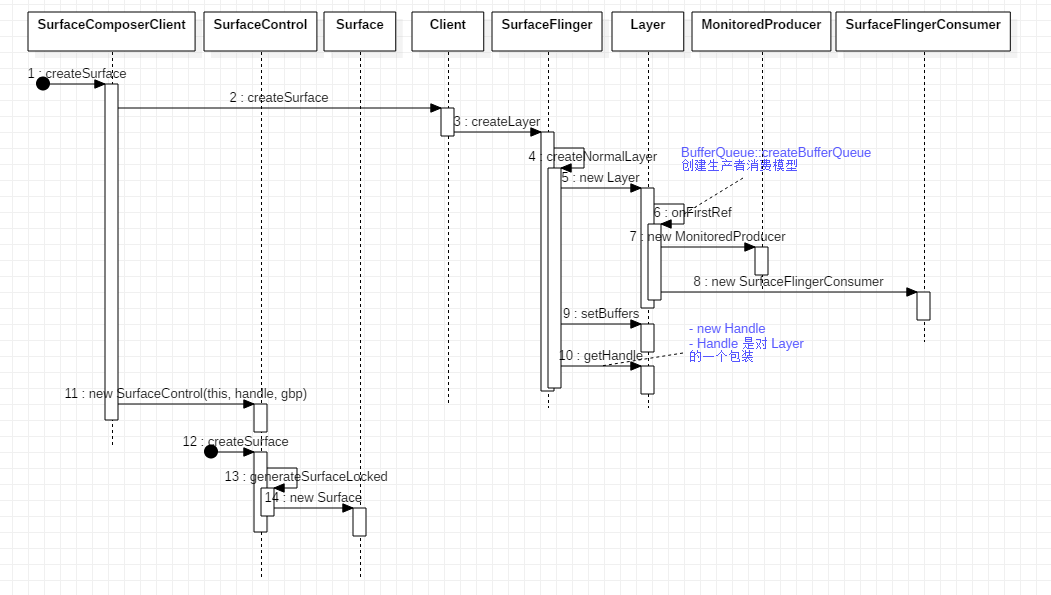
Surface 创建流程图
由客户端 SurfaceComposerClient 发起创建流程,然后由服务端 SurfaceFlinger 创建对应的 Layer ,而 Layer 在被引用时会创建生产者消费者模型的 BufferQueue ,然后再由客户端将拿到的结果传入 SurfaceControl ,最后直接实例化一个 Surface 。
创建生产者消费者模型 BufferQueue 的关键代码:
1 | // Layer.cpp |
VSYNC 垂直刷新
Android 中有 2 种 VSync 信号:屏幕产生的硬件 VSync 和由 SurfaceFlinger 将其转成的软件 Vsync 信号;软件 Vsync 后者经由 Binder 传递给 Choreographer 。Vsync 信号可将某些事件同步到显示设备的刷新周期。应用总是在 VSYNC 边界上开始绘制,而 SurfaceFlinger 总是在 VSYNC 边界上进行合成。这样可以消除卡顿,并提升图形的视觉表现。 HWComposer 对象创建过程,会注册一些回调方法;当硬件产生 VSYNC 信号时,则会回调 HWC2::ComposerCallbackBridge::onVsync 方法,然后逐级回调,下图是整个回调流程图:
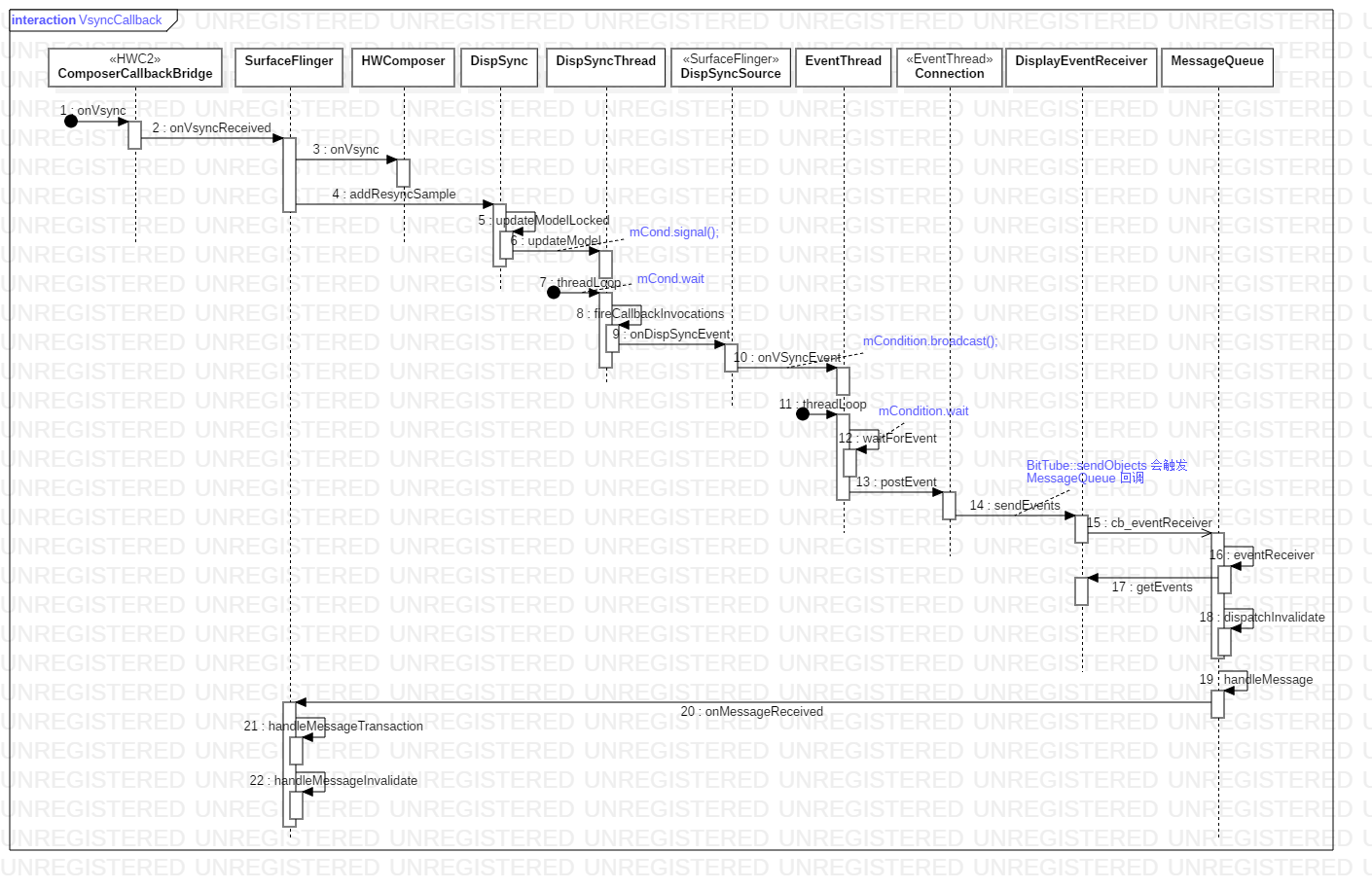
- 硬件
Vsync信号发送过来,一路执行到DispSyncThread.updateModel方法中调用mCond.signal,唤醒DispSyncThread线程 DispSyncThread线程中执行EventThread::onVSyncEvent中调用mCondition.broadcast唤醒EventThread线程EventThread线程中执行DisplayEventReceiver::sendEvents方法,会调用BitTube::sendObjects;在MessageQueue::setEventThread中,我们设置了BitTube事件的回调,当收到数据会触发MQ.cb_eventReceiver;根据Handler消息机制,进入SurfaceFlinger主线程SurfaceFlinger主线程进入到MesageQueue的handleMessage,最终调用SurfaceFlinger::handleMessageRefresh
客户端通知 SurfaceFlinger 刷新
BufferQueueProducer::queueBuffer 函数中会调用 listener->onFrameAvailable ,而这最终会触发服务端的 Layer::onFrameAvailable ,从而通知 SurfaceFlinger 合成图像。我们先看 onFrameAvailable 接口的继承关系:
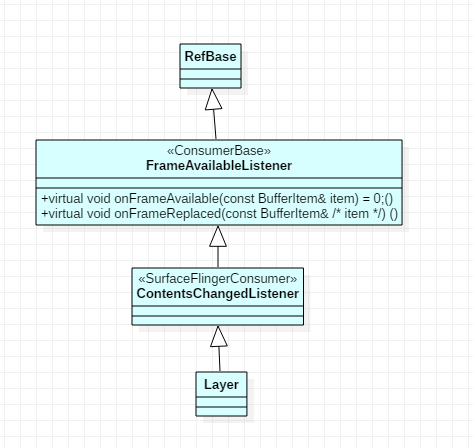
从 Surface 创建流程中贴出的 Layer::onFirstRef 代码中可以看到,在 Layer 中设置了 mSurfaceFlingerConsumer->setContentsChangedListener 监听事件,所以 BufferQueueProducer::queueBuffer 会触发 Layer::onFrameAvailable 事件,下面是完整的请求流程。
客户端在 BufferQueue 中生产完图像数据后,通知 SurfaceFlinger 刷新界面的流程图:
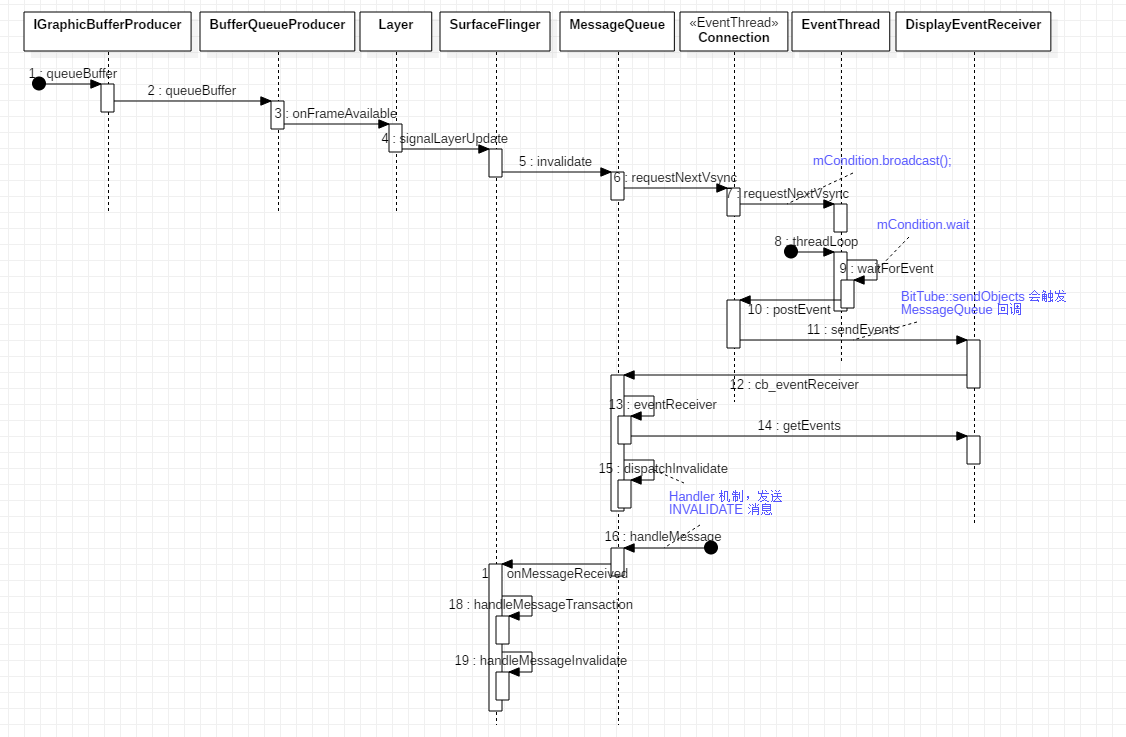
后续
WMSLayer合成流程- 结合
Camera熟悉图形显示中Buffer相关流程 Choreographer及掉帧分析- 详述
SurfaceTexture, SurfaceView, GLSurfaceView等区别 - 工具
dumpsys SurfaceFlinger输出的LOG分析 screencap命令及源码分析Systrace性能工具分析