Java 集合(也称为容器),是将多个元素组合成一个单元的对象。分为两大类: Collection 和 Map,常用集合为 List 、Set、Map;本文源码分析基于 JDK 1.8 。
基础
概念
集合框架是用于表示和操作集合的统一体系结构,所有集合框架包含以下内容:
- 接口
Interfaces
表示集合的抽象数据类型,接口允许独立于其表示的细节来操纵集合。 - 实现
Implementations
集合接口的具体实现,本质上它们是可重用的数据结构。 - 算法
Algorithms
这些是对实现集合接口的对象,执行有用计算(如搜索和排序)的方法,算法被认为是多态的:相同的方法可以用在集合接口的不同实现上,算法是可重用的功能。
除了 Java Collections Framework 之外,最着名的集合框架示例是 C ++ 标准模板库 STL 。
for-each
for-each 循环是加强型 for 循环,用来循环遍历集合和数组,JDK 5.0 引入的特性。其语法如下:
1 | for(type element: array) { |
Iterator
即迭代器,也是一种设计模式,允许访问一个聚合对象而无需暴露内部实现。是一种”轻量级”对象,只能单向遍历。
1 | // java.util.Iterator.java |
Iterable
可迭代的,实现了这个接口的类表示可迭代的,并且支持 for-each 循环遍历。
1 | // java.lang.Iterable.java |
接口
Java 集合框架的基础是:核心集合接口,它封装了不同类型的集合,这些接口可以独立的操作集合。类图结构如下:
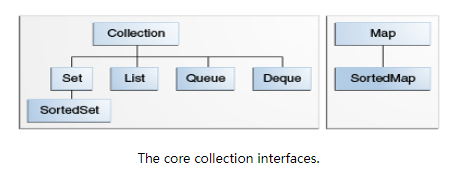
集合框架都是使用的是泛型,也就是说实例化时必须要指定具体类型。集合框架包含两个大的类型:
Collection:我们常说的集合Map:保存具有映射关系的数据,包含键和值。键不能重复,每个键只有一个对应的值
Collection 接口表示一组称为其元素的对象,Java 平台不提供此接口的任何实现,只有子接口的实现。它有四个常用的子接口:
Set:表示不能包含重复元素的集合List:表示元素是有序的集合,有时也称为序列Queue:队列,通常指先进先出FIFO集合,集合的操作都集中在队列某一端Deque:双端队列,它实际是Queue的子类(感觉并不能和Queue并列讨论),可以在队列两端操作集合;它实现了栈LIFO和队列FIFO两种数据结构
SoretedSet, SoretedMap 表示按升序排好序的集合或键值对。
Collection 接口
1 | public interface Collection<E> extends Iterable<E> { |
Collection 接口是可迭代的,它提供了集合的一些基本操作:
- 集合大小,是否为空,是否包含,增加,删除,是否相等,全部清除
- 迭代访问
- 集合转换为数组
- 集合间操作:集合是否包含指定集合,集合添加到目标集合,从集合中移除指定集合
- 集合取交集:
retainAll,如果和指定集合有交集,则当前集合只保留交集部分;否则当前集合变为空 - 移除符合特定条件的元素
removeIf - 支持并行处理
Spliterator - 支持转换为流
Stream
List 接口
在介绍 List 接口前,先看看 ListIterator 迭代器的定义:
1 | public interface ListIterator<E> extends Iterator<E> { |
ListIterator 继承了 Iterator ,即是一个加强版的迭代器。 ListIterator 是 List 的专有接口,它在迭代时可以向前或者向后迭代,并且支持返回索引值。接下来看 List 接口定义:
1 | public interface List<E> extends Collection<E> { |
List 接口中除了 Collection 定义的方法以及重复定义的方法外,新增了一些以索引 index 相关的操作:
- 集合插入操作:在指定位置插入集合
addAll(int index, Collection<? extends E> c) - 集合替换操作:按照指定一元运算符计算并替换当前集合所有的元素
replaceAll(UnaryOperator<E> operator) - 集合排序操作:按照指定排序方式,将当前集合内部排序
sort(Comparator<? super E> c) - 集合截取操作:给定两个指定位置,截取这部分元素集合
List<E> subList(int fromIndex, int toIndex) - 索引
Index操作:获取指定位置元素、设置指定位置元素、在指定位置添加元素、移除指定位置元素、指定元素的第一个位置indexOf、指定元素的最后一个位置lastIndexOf - 支持
ListIterator迭代器:既可以向前遍历,也可以向后遍历
Queue 接口
1 | public interface Queue<E> extends Collection<E> { |
Queue 接口继承了 Collection ,并重新定义了如下几个方法:
add/offer:向队列中添加一个元素remove/poll:删除并取出队首元素element/peek:获取队首元素,但在队列中不删除该元素
这些功能相似,却有两个独立方法的区别是:抛出异常!
add方法在容量有有限制的队列中,添加元素超出容量限制时会抛出异常;而offer只会返回falseremove方法在队列为空时,删除会抛出异常;而poll只会返回nullelement方法在队列为空时,取出队首元素抛出异常;而peek只会返回null
所以它们在选择并使用时,主要是考虑当前程序是否需要处理异常;当然也和集合的具体实现类有关,取决于集合实现类是否严格按照方法的定义去实现了。
Deque 接口
1 | public interface Deque<E> extends Queue<E> { |
Deque 继承了 Queue ,属于双端队列,接口中的方法明显增多,主要是多出了双端操作:
- 不管是增加还是删除,都提供队首或队尾操作
- 实现数据结构队列的操作时:从队尾插入,从队首取出,模拟
FIFO过程 - 实现数据结构栈的操作时:从队首插入,从队首取出,模拟
LIFO过程 - 支持指定元素操作:从队首开始删除第一个匹配的指定元素
removeFirstOccurrence/remove,从队尾开始删除第一个匹配的指定元素removeLastOccurrence,判断是否包含指定元素contains - 支持双端遍历:从队首开始遍历
iterator;从队尾开始遍历descendingIterator
Set 接口
1 | public interface Set<E> extends Collection<E> {...} |
Set 继承了 Collection ,并没有增加任何新的方法,特点是集合中没有重复元素,最多只允许一个 null 元素。Set 的实现类都是基于 Map 来实现的:HashSet 是通过 HashMap 实现的;TreeSet 是通过 TreeMap 实现的。
Map 接口
1 | public interface Map<K,V> { |
Map.Entry 接口表示 Map 的每个基本元素,它提供如下功能:
getKey获取当前元素的键getValue/setValue获取和设置当前元素的值- 判断当前元素是否相等
hashCode, equals - 按键比较元素
comparingByKey,支持指定比较器 - 按值比较元素
comparingByValue,支持指定比较器
Map 接口提供的功能包含:
- 基本操作:大小,判断是否为空,是否包含键,是否包含值,清除图中所有元素,是否相等
- 键值对相关操作
- 集合操作:获取图中所有键
keySet,获取图中所有值values,获取图中所有元素entrySet - 整个图操作:
forEach遍历图中所有元素,每个元素按照指定方法操作;replaceAll遍历图中所有元素,每个元素按照指定方法操作后的结果,替换键对应的值
SoretedSet 接口
1 | public interface SortedSet<E> extends Set<E> { |
SoretedSet 接口根据对象的比较顺序排序的集合。
NavigableSet 接口
1 | public interface NavigableSet<E> extends SortedSet<E> { |
NavigableSet 接口继承了 SoretedSet,所以它是有序的;具有导航方法返回小于、小于等于、大于等于、大于给定元素的元素。
SoretedMap 接口
1 | public interface SortedMap<K,V> extends Map<K,V> { |
SoretedMap 接口表示按照键值升序排序的 Map,也可以按照指定比较器排序。
NavigableMap 接口
1 | public interface NavigableMap<K,V> extends SortedMap<K,V> { |
NavigableMap 接口继承了 SortedMap,所以它是有序的;具有针对给定搜索目标返回最接近匹配项的导航方法,比如小于、小于等于、大于、大于等于某个键的元素等。
抽象实现类
AbstractCollection 抽象类
1 | public abstract class AbstractCollection<E> implements Collection<E> { |
抽象集合类 AbstractCollection 中,已经实现的方法,基本都是使用最原始的迭代器 Iterator 来遍历实现的;但 iterator 方法是抽象的,也就是说迭代器由具体类来实现。
- 抽象类包含两个抽象方法:
iterator, size add方法必须由子类重写,否则抛出异常
AbstractList 抽象类
1 | public abstract class AbstractList<E> extends AbstractCollection<E> |
几个内部类及对应功能:
Itr:迭代器的普通实现,顺序迭代ListItr:迭代器实现了ListIterator,即支持向前,也支持向后迭代SubList:AbstractList列表的一部分,从开始到结束索引这部分的列表RandomAccessSubList:支持随机访问
AbstractSequentialList 抽象类
1 | public abstract class AbstractSequentialList<E> extends AbstractList<E> { |
AbstractSequentialList 抽象类继承了 AbstractList,重写了添加、删除、获取、设置等方法,从具体实现可以看出它只支持按次序访问;而 AbstractList 还支持随机访问的。唯一的抽象方法是 listIterator ,按照索引返回 ListIterator 迭代器。
AbstractQueue 抽象类
1 | public abstract class AbstractQueue<E> |
AbstractQueue 抽象类实现了 Queue 接口的 add, remove, element 三个方法;Queue 接口定义的其他方法由子类去实现。
AbstractSet 抽象类
1 | public abstract class AbstractSet<E> extends AbstractCollection<E> |
AbstractSet 抽象类仅实现了 equals, hashCode, removeAll 三个方法。
AbstractMap 抽象类
1 | public abstract class AbstractMap<K,V> implements Map<K,V> { |
两个内部类,实现了 Entry 元素接口:
SimpleEntry:可以通过set修改值SimpleImmutableEntry:线程安全,不能通过set修改元素的值
AbstractMap 抽象类中,定义了数据存储方式:
Set<K> keySet:存储键,键是不可重复的,所以使用了SetCollection<V> values:存储值,普通集合满足
实现类分类
常用集合实现类

存储方式分类
任何数据结构的数据存储都只有两种:数组和链表;并基于这两种衍生出其他结构:树,hash 表,图等。本文介绍的集合,就按照其存储方式有:
Hash table哈希表实现:HashMap, HashSetArray数组实现:ArrayList, ArrayDequeTree树实现:TreeMap, TreeSetLinked list链表实现:LinkedListHash table + Linked list哈希表加链表混合实现:LinkedHashMap, LinkedHashSet
按照接口分类
List接口:ArrayList, LinkedList, Vector, StackSet接口:HashSet, TreeSet, LinkedHashSet, EnumSetMap接口:HashMap, TreeMap, LinkedHashMap, EnumMapQueue/Deque接口:ArrayDeque, LinkedList
ArrayList 及集合操作
定义
1 | public class ArrayList<E> extends AbstractList<E> |
ArrayList 的特点:
- 它是一个列表,支持随机访问,也支持顺序访问
- 是一个数组队列,支持容量动态扩展,每次扩展 1.5 倍
Object[] elementData数组存储所有的元素,默认容量大小为 10size是动态数组的实际大小- 不是线程安全的
遍历方式
1 | Iterator iterator = lists.iterator(); |
不管是哪种遍历方式,访问顺序都是一样的,都是按照存入顺序访问的。集合中 for-each 访问效率是最高的,实际测试 ArrayList 也是如此。
数组转换
1 | Object[] toArray(); |
其中 toArray() 可能会抛出现类型转换异常,通常使用泛型 toArray 实现:
1 | Integer[] values = lists.toArray(new Integer[0]); |
fail-fast 机制
fail-fast 机制是集合 Collection 中的一种错误机制,当多个线程对同一个集合的内容进行操作时,就可能会产生 fail-fast 事件:即抛出 ConcurrentModificationException 异常。
1 | private void testFailFast(){ |
示例中,在线程遍历集合数据时,另一个线程删除了集合中的一个数据,因为 ArrayList 并不是线程安全的,所以会产生 fail-fast 事件。可以使用 concurrent 包中的 CopyOnWriterArrayList 来代替。
常用集合实现类
LinkedList
1 | public class LinkedList<E> |
LinkedList 的特点:
- 数据存储结构是链表实现,链表中每个元素使用
Node表示,它记录了链表前后的元素,以及元素当前值 first表示链表头结点;last表示链表尾节点;size表示链表中元素个数- 链表顺序访问效率会非常高,随机访问需要遍历链表效率低
- 实现了
List接口,并继承了AbstractSequentialList,也就是可以当做列表使用;支持随机访问和顺序访问 - 实现了
Deque接口,也就是可以当做双端队列使用,*实现了栈LIFO和队列FIFO*两种数据结构 - 不是线程安全的
Vector
1 | public class Vector<E> |
Vector 的特点:
- 继承了
AbstractList并实现了List接口,所以它是一个列表 Object[] elementData数组存储所有的元素,该列表使用方法同ArrayList类似- 所有的方法都是用了
synchronized关键字,也就是说Vector是线程安全的
Stack
1 | public class Stack<E> extends Vector<E> { |
Stack 的特点:
- 继承了
Vector,也就是说实质上只是一个同步的ArrayList - 实现了
push, pop, peek方法,即可以当做栈来使用,可以认为是一个同步栈
HashMap
1 | public class HashMap<K,V> extends AbstractMap<K,V> |
HashMap 核心是使用了”数组+链表”的存储方式,使用拉链法解决冲突(将冲突的 key 的对象放入链表中),Java 1.8 中链表长度大于 8 时,链表转换为红黑树结构;参考:Java HashMap 简介 。HashMap 的 key, value 都可以为 null ;但只允许出现一个为 null 的键。
LinkedHashMap
1 | public class LinkedHashMap<K,V> |
LinkedHashMap 类是哈希表+链表实现的集合,有如下几个特点:
- 继承
HashMap,所以数据存储和HashMap一致 LinkedHashMap.Entry中增加了after, before来记录当前元素的前后元素,形成链表head, tail表示元素链表的头和尾accessOrder表示LinkedHashMap的遍历顺序:true表示按照访问顺序输出(也就是每次访问一个元素后,这个元素都会移动到链表尾部),false表示按照插入顺序输出(有序性);该变量是final的,只在构造方法中赋值,默认为falsenewNode新建节点时,除了存储数据,同时会将该节点插入链表尾部LinkedEntrySet遍历时返回的数据集,数据迭代器是按照链表顺序输出的
accessOrder 特性:
- 访问顺序:利用这个特性可以实现
LRU: Least Recently Used缓存,即最近最少使用原则;链表尾总是保存最近使用的元素,当数据过多时,总是删除链表头部元素 - 插入顺序:解决了
HashMap元素随机遍历的问题,可以按照插入顺序输出元素
遍历时返回的是 LinkedEntrySet,而它使用的迭代器为 LinkedEntryIterator ,迭代器中重写了访问下一个元素的方式, nexNode 会从链表头部开始逐个访问。也就是说,遍历始终是从链表头部到尾部的:
- 插入顺序输出:当新建节点
newNode时,该节点同时会插入链表尾部,即链表维持了插入顺序 - 访问顺序输出:当访问了一个节点后
get,会同时将被访问节点移动到尾部afterNodeAccess,即链表维护了访问顺序(没有被访问过的还是插入顺序)
HashTable
1 | public class Hashtable<K,V> |
HashTable 是一个线程安全的散列表,所有的方法都有 synchronized 关键字,但是通常推荐使用并发包中的 ConcurrentHashMap 。
TreeMap
1 | public class TreeMap<K,V> |
TreeMap 类是红黑树的 Java 实现,存储有序的键值对;参考 算法 - 红黑树 。
HashSet
1 | public class HashSet<E> |
HashSet 表示没有重复元素的集合,它是由 HashMap 来实现数据存储的,所以不保证元素的顺序。有如下几个特点:
HashSet公开构造方法,默认使用的是HashMap存储数据;数据是无序的HashSet还有一个包内可见的构造方法,主要是供子类LinkedHashSet调用的,使用的是LinkedHashMap来存储数据;数据是有序的HashSet的每个元素对应HashMap中一个key,遍历时即是遍历所有的key
LinkedHashSet
1 | public class LinkedHashSet<E> |
LinkedHashSet 继承 HashSet,并没有提供额外的功能,仅仅是构造方法调用父类设置容量、装载因子等,而最大的特点是只调用父类包内可见构造方法,即使用 LinkedHashMap 来存储数据,所以数据是有序的。
TreeSet
1 | public class TreeSet<E> extends AbstractSet<E> |
TreeSet 表示有序集合,从构造方法可以看出,它是由 TreeMap 实现的有序性。
ArrayDeque
1 | public class ArrayDeque<E> extends AbstractCollection<E> |
ArrayDeque 类是双端队列的数组实现:
Object[] elements数组存储双端队列元素head, tail表示队头和队尾索引
PriorityQueue
1 | public class PriorityQueue<E> extends AbstractQueue<E> |
PriorityQueue 类是优先队列的 Java 实现,默认为小根堆;参考 算法 - 优先队列 - 二叉堆 。
工具类
Arrays
1 | public class Arrays { |
Arrays 主要提供的功能:
sort排序:使用DualPivotQuicksort对数组快速排序parallelSort并行排序:数据足够大时,使用ArraysParallelSortHelpers来排序,通过ForkJoinTask多线程排序parallelPrefix并行计算:对数组的每个元素,执行BinaryOperator二元计算(计算结果参与下一个元素继续计算);也是多线程操作binarySearch对有序数组进行二分查找equals对给定两个数组进行比较,数组元素是否完全相同fill使用给定值对数组进行填充copyOf拷贝:将原有数组拷贝到指定新长度的数组中;数组动态扩容经常会有数组拷贝asList数组转换为列表hashCode计算给定数组的hashCodesetAll/parallelSetAll根据给定计算公式,更新数组每个元素stream数组转换为流
Collections
1 | public class Collections { |
Collections 主要提供的功能:
sort列表按照给定比较器排序binarySearch已经排好序的列表,二分查找reverse反转列表中的元素shuffle将列表随机移位;特别是算法中,避免出现最坏时间复杂度,通常需要将输入序列打乱swap交换列表中的两个元素fill列表中填充指定元素copy拷贝列表中的元素到另一个列表rotate将列表中的元素循环移位distance,默认向左移动indexOfSubList如果子列表存在,返回索引值replaceAll将列表中所有指定旧元素替换为新元素min, max找出集合中的最小值,最大值unmodifiableCollection根据给定集合,返回一个不可修改的集合;相当于集合每个元素及状态finalsynchronizedCollection根据给定集合,返回一个同步操作的集合;该集合上所有的操作都是同步的,线程安全的checkedCollection根据给定集合,返回一个类型检查的集合;集合上的添加等操作,会做类型检查emptyList返回一个空的列表;返回空集合操作singletonList返回单个元素列表;单个元素集合操作frequency返回集合中元素出现的次数disjoint判断两个集合是否有共同元素;有则返回trueasLifoQueue双端队列转换为LIFO先进先出队列
集合间异同
集合和数组
- 数组
大小固定,同一个数组只能存放一种基本类型或者对象。定义时需要声明存储类型。 - 集合
大小动态改变,只能存储对象。集合是对数组的封装,所以数组比集合存取速度要快。
1 | // 1. 数组 |
List 接口
AbstractList, AbstractSequentialListAbstractList既支持随机访问,也支持顺序访问;AbstractSequentialList只支持顺序访问。ArrayList
数组列表,支持数组动态扩容;数组特性:访问效率高,插入和删除需要移动数据效率低;非线程安全。LinkedList
链表列表,双向链表;链表特性:插入和删除效率高,访问效率低;非线程安全。Vector
数组列表的同步实现,拥有ArrayList使用特性,但是是线程安全的。Stack
继承Vector,模拟了栈的特性LIFO,是线程安全的。
Map 接口
Map, SortedMap, NavigableMapMap的三个基本接口;SoretedMap表示存储有序的键值对;NavigableMap继承了SoretedMap,额外提供键值对导航方法,支持大于、小于、小于等于等操作。HashMap
基于拉链法实现的散列表,使用数组+链表存储键值对;链表长度大于 8 时转换为红黑树;非线程安全。HashTable
线程安全的散列表,不过通常建议使用并发包中的ConcurrentHashMap来代替。TreeMap
红黑树的Java实现,散列表中存储的键值对是无序的,但按大小排序;非线程安全。LinkedHashMap
实现方式为:链表+散列表;HashMap存储数据,链表保持元素的有序性;非线程安全。
Set 接口
HashSetHashSet依赖于HashMap,它实际上是通过HashMap实现的。HashSet中的元素是无序的;非线程安全。TreeSetTreeSet依赖于TreeMap,它实际上是通过TreeMap实现的。TreeSet中的元素是无序的,但按大小排序;非线程安全。LinkedHashSetHashSet依赖于LinkedHashMap,它实际上是通过LinkedHashMap实现的。LinkedHashSet的元素是有序的;非线程安全。
Queue/Deque 接口
LinkedList
双端队列的链表实现。ArrayDeque
双端队列的数组实现。PriorityQueue
优先队列的Java实现,默认为小根堆。
小结
在使用中,集合的选取主要从多线程环境、数据访问的特性(数组、链表)、有序性、使用哪种接口来考虑。
其他
有序无序
有序、无序是指在进行插入操作时,插入位置的顺序性;先加入的元素位置在前,后加入的元素位置在后,这就是有序,反之为无序。
所以通常所说 List 是有序的,指的是加入和删除元素都是按照加入顺序进行;而 Set 通常是通过 Map 来实现的,元素加入顺序为随机的。
而和有序性容易混淆的是排序,排序是指集合内的元素是否按照升序或降序来排序,和插入顺序并没有关系。
动态扩容特性
如果使用数组来存储元素,集合默认都是支持动态扩容的,但是动态扩容涉及到整个数组拷贝,所以在使用集合前,预估集合数据大小,减少扩容次数能提高效率。
线程安全
java.util 包中的集合大部分都不是线程安全的:ArrayList, LinkedList, HashMap, TreeMap, HashSet, TreeSet, ArrayDeque, PriorityQueue 等,只有 Vector, Stack, HashTable 是线程安全的。
在多线程环境下,建议使用并发包中的集合:CopyOnWriterArrayList, ConcurrentHashMap 等。
遍历
通常 Collection 接口实现类都使用 for-each 遍历;Map 接口实现类使用 entrySet 来遍历。
1 | // 1. 遍历 Collection |
后续
- 每个集合类源码分析
- 并发包中的集合
- Google Guava 中的集合