算法:二叉查找树。
二叉查找树
定义
二叉查找树 Binary Search Tree,又称二叉排序树 BST: Binary Sort Tree 、二叉搜索树。
二叉查找树:是一颗二叉树,其中每个节点都含有一个 Comparable 的键(以及相关联的值),其中每个节点的键都大于左子树中的任意节点的键,并且小于右子树中的任意节点的键。
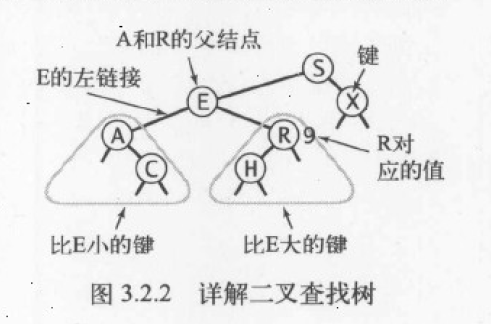
数据表示
一颗二叉查找树代表了一组键值的集合,而同一个集合可以有多颗不同的二叉查找树表示。但这些二叉查找树在垂直方向上的投影:都是固定顺序的,由小到大的排序顺序。
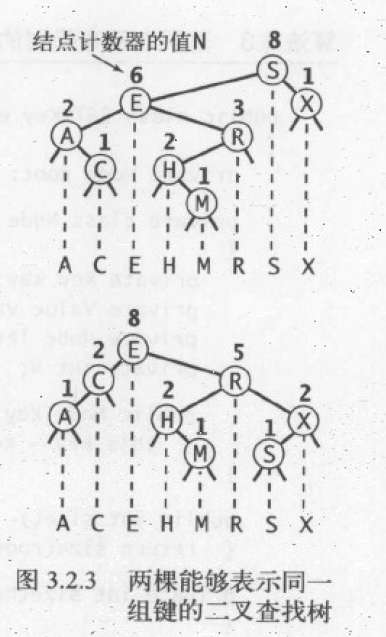
数据结构解析
节点
1 | private class Node { |
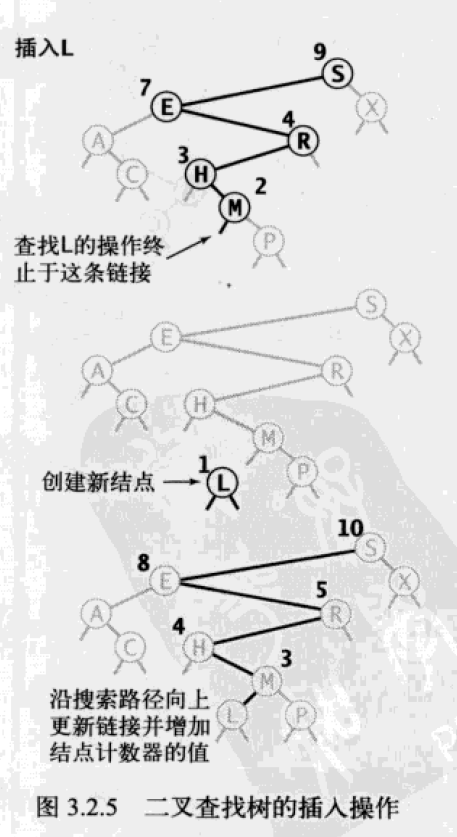
插入 insert
插入操作用来构造一颗二叉查找树。
1 | public void insert(Key key, Value val){ |
插入示意图:
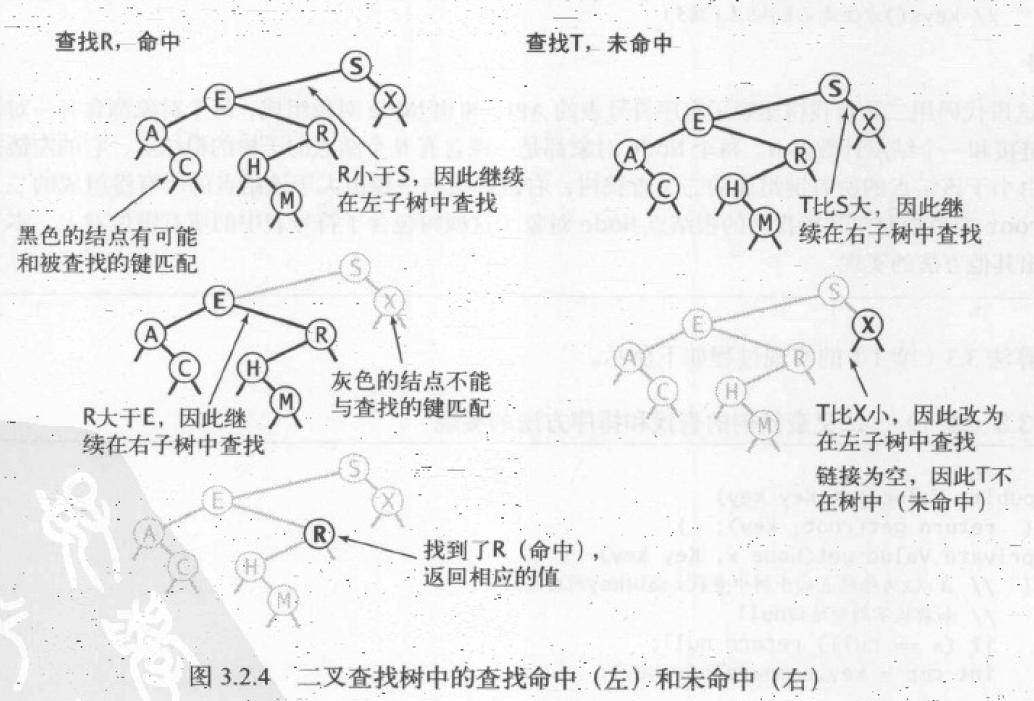
查找 find
在二叉查找树中,查找指定的关键字。
1 | public Value find(Key key){ |
查找示意图:
性能分析
二叉查找树的算法性能取决于二叉树的形状,而二叉查找树的形状取决于键被插入的先后顺序。最好情况下是完全平衡的二叉树,N 个节点查找的时间复杂度为 logN;最坏情况下时间复杂度会达到 N 。
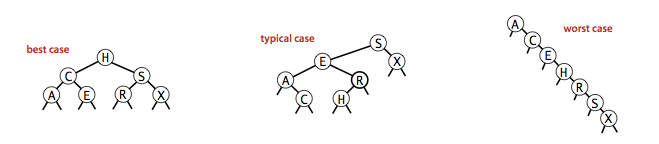
有序性
二叉查找树得到广泛应用的一个重要原因是:始终能保持键的有序性,不管是插入、删除等操作,二叉查找树始终是一个排好序的数据结构。
最大值和最小值
- 最大值始终在右子树
- 最小值始终在左子树
1 | // 最小值 |
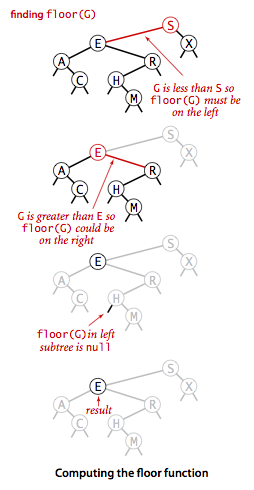
向上取整和向下取整
- 向上取整:找到大于等于指定
key的最小key - 向下取整:找到小于等于指定
key的最大key
1 | // 向上取整 |
向下取整搜索示意图:
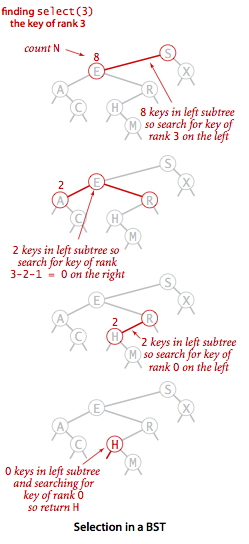
选择和排名
- 选择:找出第
k个排序位置的键值 - 排名:给定键值
key的排序位置
二叉查找树的节点中 size 保存了以该节点为根的子树,一共包含多少子节点(包含自己),计算方式为:size(r) = size(r.left) + size(r.right) + 1;。不管是选择还是排名,都和位置有关系,也就是和节点数有关。所以计算位置时,直接以节点数来判断。
1 | // 选择 |
选择示意图:
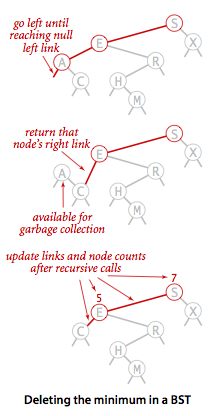
删除最大键和最小键
- 删除最小键
最小键的左子树一定为空,右子树可以为空或者非空;删除时将右子树赋给父节点左子树。 - 删除最大键
最大键的右子树一定为空,左子树可以为空或者非空;删除时将左子树赋给父节点右子树。 - 更新节点数
删除键值时,需要注意更新所在子树中每个节点的size值。
1 | // 删除最小值 |
删除最小值示意图:
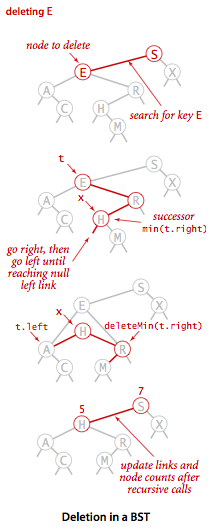
删除指定键值
删除最小值或最大值的方法,只适合删除包含一个子节点或没有子节点的节点。但如果一个节点拥有两个子节点,该如何删除?T.Hibbard 在 1962 年提出了解决方案:删除一个节点时,使用其后继节点来填补它的位置。后继节点为其右子树中的最小节点(当然也可以取左子树的最大节点),这样替换后仍能保持二叉查找树的有序性。详细步骤如下:
- 被删除的节点
x保存为t - 将
x赋值为后继节点,即min(t.right) x的右子树删除最小值,并更新x右子树x的左子树保持不变- 递归更新子树所有节点数
1 | public void delete(Key key) { |
删除指定键值示意图:
范围查找
使用队列保存指定范围内查找到的键值。
1 | // 输出所有键值 |
小结
二叉查找树的几个特点:
- 性能和输入序列顺序高度相关
- 插入和查找的平均时间复杂度都为
logN - 插入、删除等操作,始终能保持键的有序性
参考文档
- 《算法:第四版》 第 3 章
- 二叉查找树动画演示